


百亿原子级分子动力学模拟不仅是理解物质世界本质的“显微镜”,更是驱动技术创新的 “计算器”。它通过突破尺度限制,将原子世界的规律与人类现实需求直接连接,从新材料、新药研发到应对全球挑战,其价值正渗透至科学与工程的每个角落,成为第四次工业革命中计算科学与实验科学深度融合的标志性工具。
从微观到介观/宏观的鸿沟
在探索物质奥秘、设计新型材料的征途上,密度泛函理论(DFT)作为第一性原理计算的基石,以其卓越的精度揭示了原子和电子层面的相互作用,成为理解材料本征性质不可或缺的工具。然而,DFT的计算成本随着体系原子数的增加呈指数级增长,这将其应用范围牢牢限制在数百至数千原子的小尺度体系内。
当我们试图理解材料在真实服役环境下的复杂行为——如裂纹的萌生与扩展、位错网络的演化、辐照损伤的累积、相变的动力学过程、或纳米结构材料的大尺度变形机制——这些关键现象往往发生在介观甚至宏观尺度,涉及数百万乃至百亿原子的集体运动和长时间演化。DFT虽精,却难以跨越这道“尺度鸿沟”,无法直接触及这些决定材料宏观性能的核心物理过程。
百亿原子MD模拟的崛起
正是为了弥合这一鸿沟,百亿原子级别的分子动力学(MD)模拟应运而生,并迅速成为计算材料科学前沿的制高点。其核心价值在于,它能在保持原子分辨率的前提下,将模拟的时空尺度拓展到足以捕捉上述关键介观现象的程度,为在原子层面“观察”和理解材料的宏观行为提供了前所未有的窗口。
这种尺度的模拟对于揭示材料失效的微观机制、预测极端条件下的材料响应、优化纳米器件的性能、乃至实现材料“基因工程”的宏伟目标都具有不可估量的研究价值。
然而,驾驭百亿原子这一庞然大物,意味着需要突破前所未有的计算极限:海量数据的存储与处理、超大规模并行计算的效率瓶颈、适用于超大体系的精确势函数开发、以及从原子轨迹中高效提取物理信息的算法创新,共同构成了这一领域最核心的难点与挑战。克服这些挑战,不仅将推动计算能力的边界,更将深刻变革我们对复杂材料体系的认识。
应用
170 亿原子的具有第一性原理精度的MD
DOI:10.1145/3503221.3508425
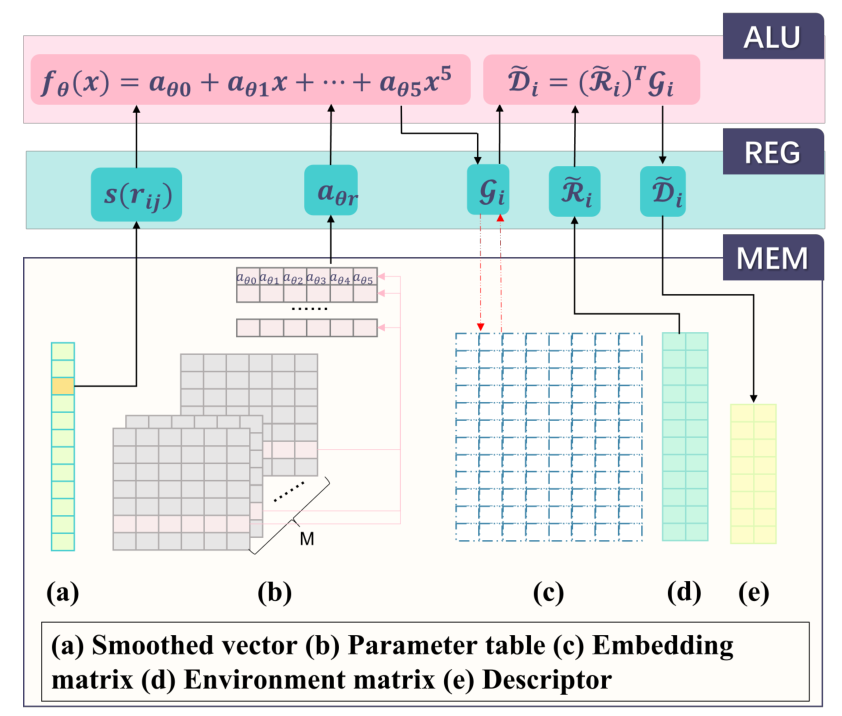
针对百亿原子级别分子动力学模拟的算力与内存瓶颈,以深度势能(Deep Potential, DP)为基础的机器学习分子动力学(MLMD)框架展现出强大的潜力。然而,如文献所示,其核心计算瓶颈在于构建描述原子局部环境的嵌入矩阵(Embedding Matrix),它消耗了超过 95% 的内存和 90% 的计算时间。
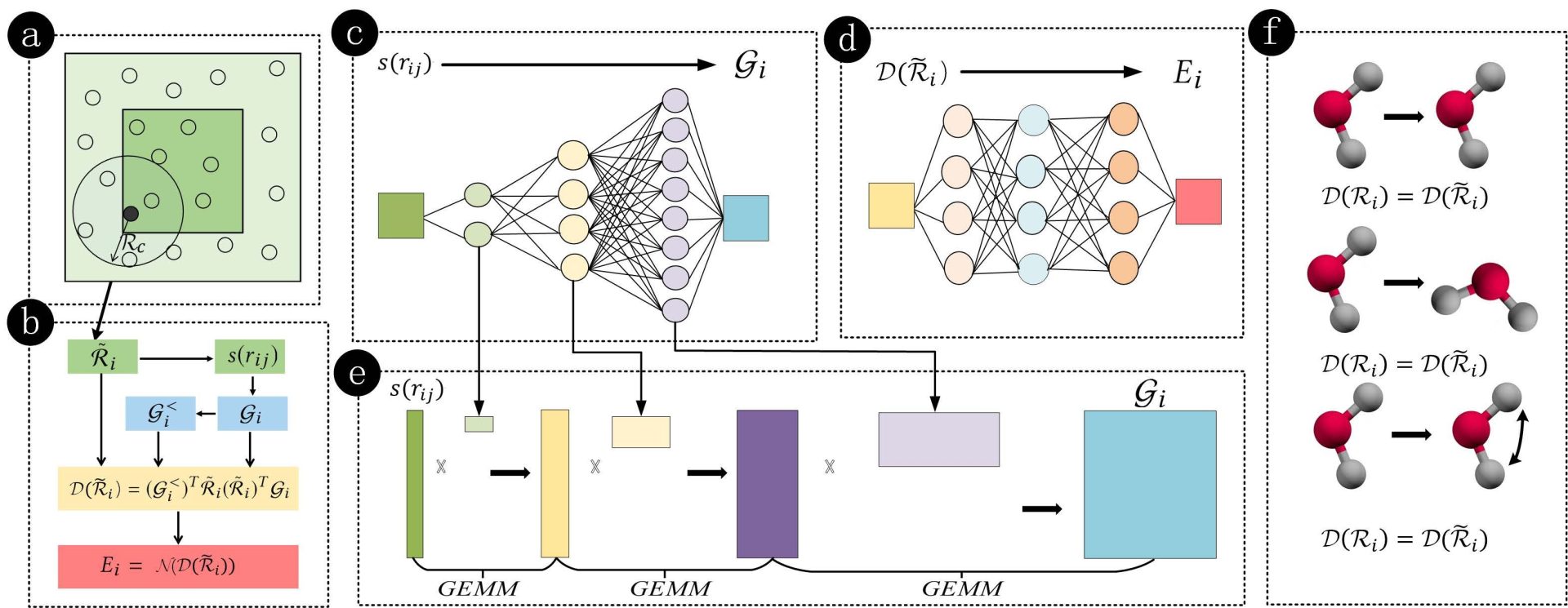
为了跨越百亿原子的门槛,该研究团队进行了革命性的算法与系统协同优化。其核心创新在于嵌入网络的查表法(Tabulation):利用魏尔斯特拉斯逼近定理,他们巧妙地用高精度(五阶)多项式替代了原本需要复杂矩阵运算的深度神经网络来计算嵌入矩阵。
这种查表法不仅将嵌入矩阵相关的浮点运算量(FLOPs)减少了惊人的 82%,更重要的是,它从根本上解耦了计算复杂度与模型深度,显著降低了内存需求和计算成本,同时保持了与原始量子力学精度模型(ab initio accuracy)相当的结果(误差达到双精度极限)。
DOI:10.1145/3503221.3508425
通过将查表法与一系列针对现代超算架构(如 GPU 的 CUDA 核融合、冗余计算消除;ARM CPU 的 SVE 向量化、MPI+OpenMP 混合并行)的深度系统优化相结合,优化后的算法实现了前所未有的性能飞跃。在 Summit (GPU) 和 Fugaku (ARM CPU) 两台顶级超算上,研究团队成功将模拟规模推至170 亿铜原子和250 亿水原子的惊人尺度,相比之前最好记录(1.27 亿原子)提升了134 倍。
同时,计算效率也获得质的提升:对于一个 1350 万铜原子的系统,在 Summit 上实现了每天模拟 11.2 纳秒的速度,比优化前加速7 倍;在 Fugaku 上对铜系统的计算效率(考虑峰值性能和功耗)甚至超越了 V100 GPU。
这项突破性工作不仅证明了百亿原子级别、兼具第一性原理精度的分子动力学模拟在当今超算上的可行性,更为研究诸如金属断裂机制、辐照损伤演化、纳米材料力学行为、复杂电化学过程(如电池)等涉及介观/宏观尺度现象的关键科学问题打开了大门,其优化的策略(模型压缩、跨核数据流优化)也为其他 HPC+AI 应用提供了宝贵洞见。
290亿原子的分子动力学模拟
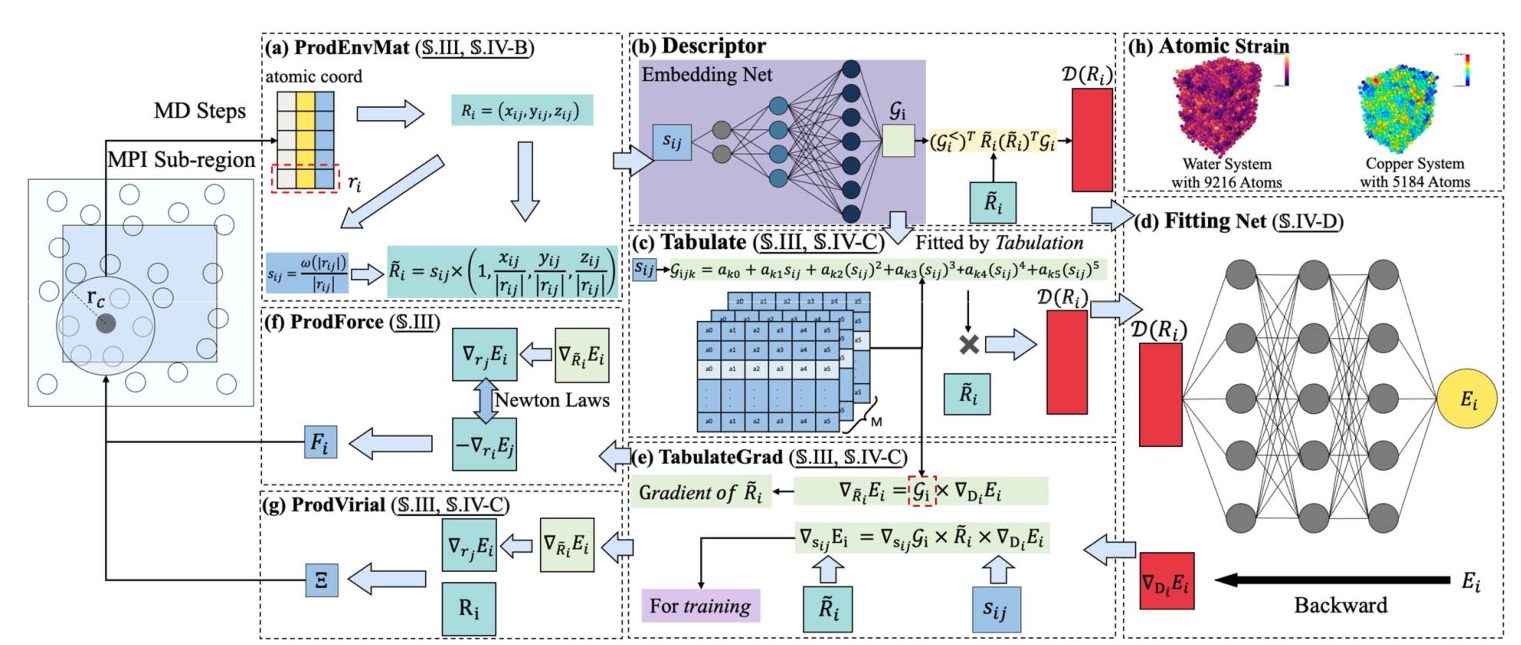
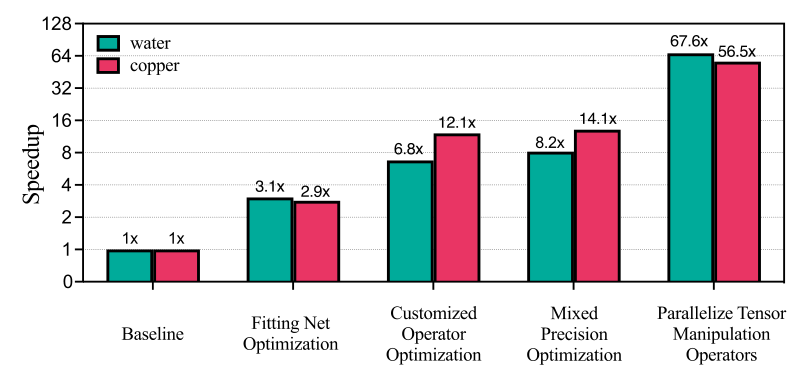
通过算法和系统创新,在新神威超级计算机上实现了大规模高精度分子动力学模拟。研究团队针对新神威的架构特点,设计了MPI、SACA 和 SIMD 的三级并行化方案,将大型分子系统均匀分区,每个 MPI 进程负责一个子区域计算,每个计算节点启动 6 个 MPI 进程,以此利用其并行计算能力。同时,对关键操作符进行定制优化,如通过计算与内存访问重叠、内核融合等技术提升性能,并采用混合精度方案减少内存访问量。
DOI: 10.1109/TC.2025.3540646
最终,优化后的DeePMD-kit 在新神威超级计算机上,水系统模拟可达到 290 亿原子,在 3500 万个核心(约占整个超级计算机的 84%)上实现了 57.1 PFLOPS 的峰值性能 ,相比之前的研究成果,规模扩大了 7.9 倍,速度提升了 1.2 倍。这一成果为研究金属力学性能、半导体器件、电池等材料和物理系统提供了有力支持,推动了相关领域的发展。
DOI: 10.1109/TC.2025.3540646
总结
这些研究不仅实证了百亿原子级别、兼具第一性原理精度的分子动力学模拟在现代异构超算上的可行性,其提出的模型压缩(查表)、核融合、冗余消除、向量化及高效混合并行等优化策略,为其他 HPC+AI 应用在多样化超算架构上突破算力与内存瓶颈提供了极具价值的范式和深刻洞见,为探索金属力学行为、辐射损伤、电池电化学过程等介观尺度现象铺平了道路。