同步辐射 因具有高亮度、高准直性和可调谐性等特点,这些特性使得同步辐射 XAFS 实验的首选光源。 XAFS 技术通过测量样品对 X 射线的吸收随能量变化的精细结构,可以提供关于样品中元素的局部化学环境和电子结构的信息。 因此,同步辐射与 XAFS 的结合,为研究材料的微观结构和性质提供了强有力的工具。 在 XAFS 分析中,原始数据的获取只是第一步,关键在于如何有效地处理和分析这些数据以提取有价值的信息。 Athena 作为一个强大的数据处理工具,除了合并数据组外,所有数据处理功能均可通过主菜单进行访问,并在主窗口中直接进行操作。内容主要包含 9大部分。
1. 数据 校准与对齐
2. 合并数据
3. 重组数据
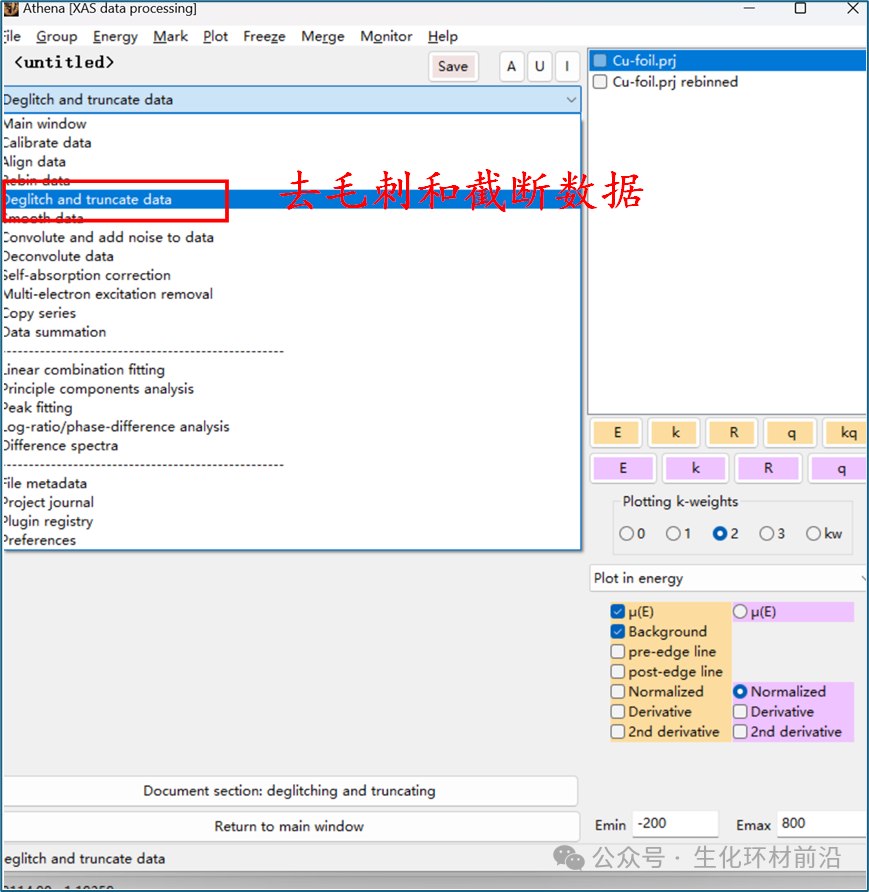
4. 去毛刺和截断数据
5. 平滑数据
6. 卷积数据组与反卷积数据
7. 自吸收近似
8. 多电子激发去除
9. 复制与数据汇总
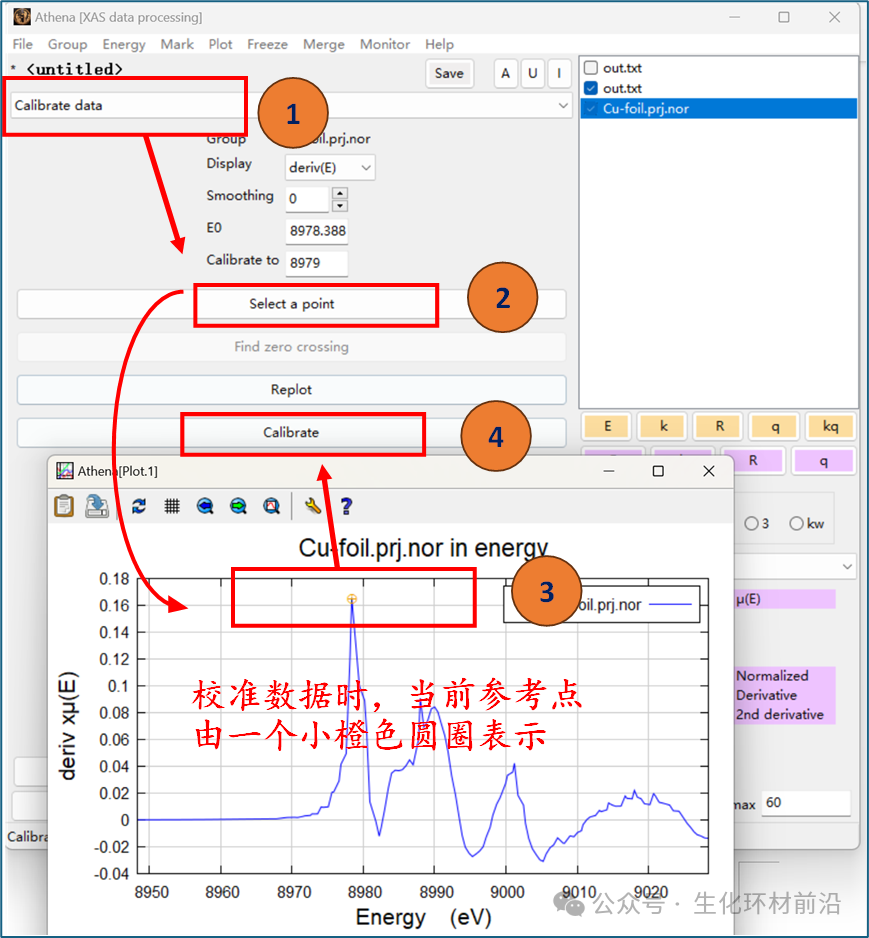
一阶导校准: 在 XAFS分析中,吸收边意味着吸收系数变化最快的位置,在一阶导数图上通常呈现为一个峰值。 操作: 可以在参数框中手动输入数值,或单击“ Select a point” 按钮,双击图中的一阶导数的最大值处。
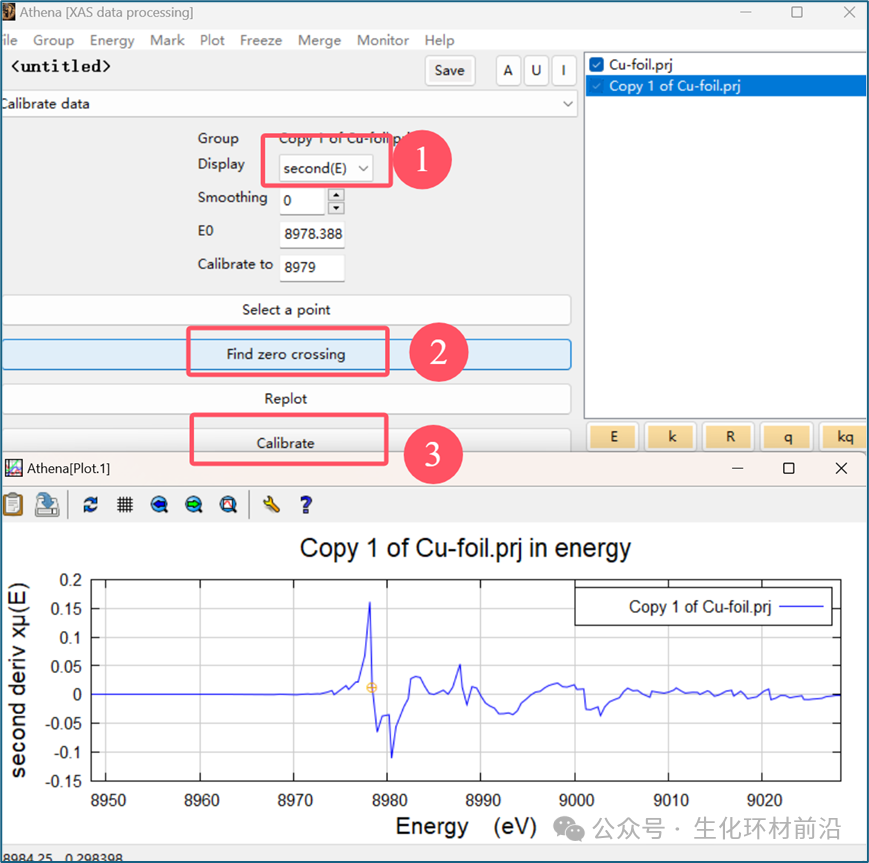
二阶导数校准: 除了一阶导数校准外,还可以使用二阶导数校准,如果使用二阶导校准,程序会默认为二阶导数的零点。 操作: 将 Display 复选框按钮选到“ second ”再点击 “Find zero crossing” 功能找到零点。
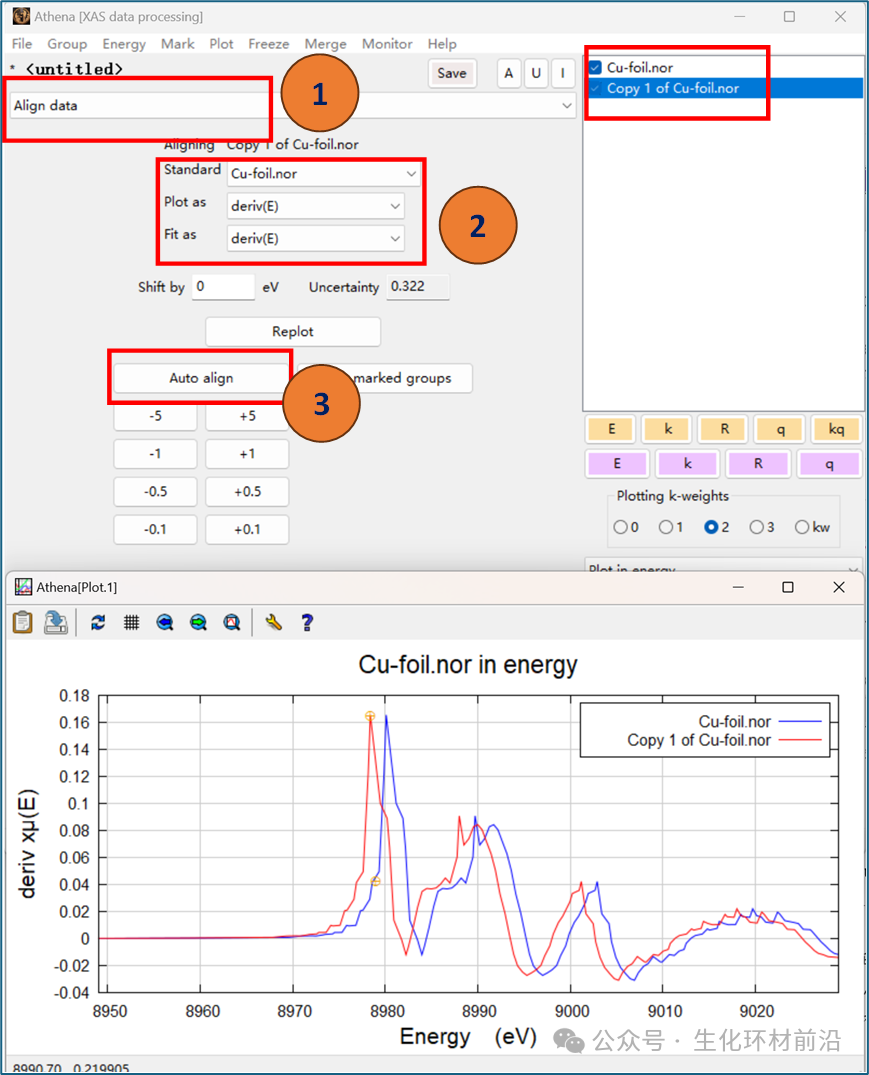
注意:在进行二阶导数校准时,前提是数据较为平滑,确保零点的准确性。 对齐数据是为了确保不同数据组的能量数据可以在同一能量尺度上进行比较或分析,从而提高数据的一致性和可比性。 手动对齐: 可以通过手动编辑 “Energy shift” 参数完成。
自动对齐: 单击 “Auto align” 按钮可执行自动对齐。 注意:对于噪音较小且偏移小于 10 V 的数据,此种方式对齐效果较好。对于偏移很大的数据,需要先手动设置 “Energy shift” 的近似值再点击 “Auto align” 。 现实中,我们测量的大多数数据质量都不佳,单次扫描通常带有噪音, 难以识别出有用的信号。对于这种情况我们可以扫描足够多的数据 ,利用中心极限定理 注意:数据可以以不同的形式合并,包括 μ(E) 、归一化 μ(E) 或 χ(k) ,但最终的 χ(R) 结果应该是一致的。不管选择哪种形式合并,最终的数据影响不大。
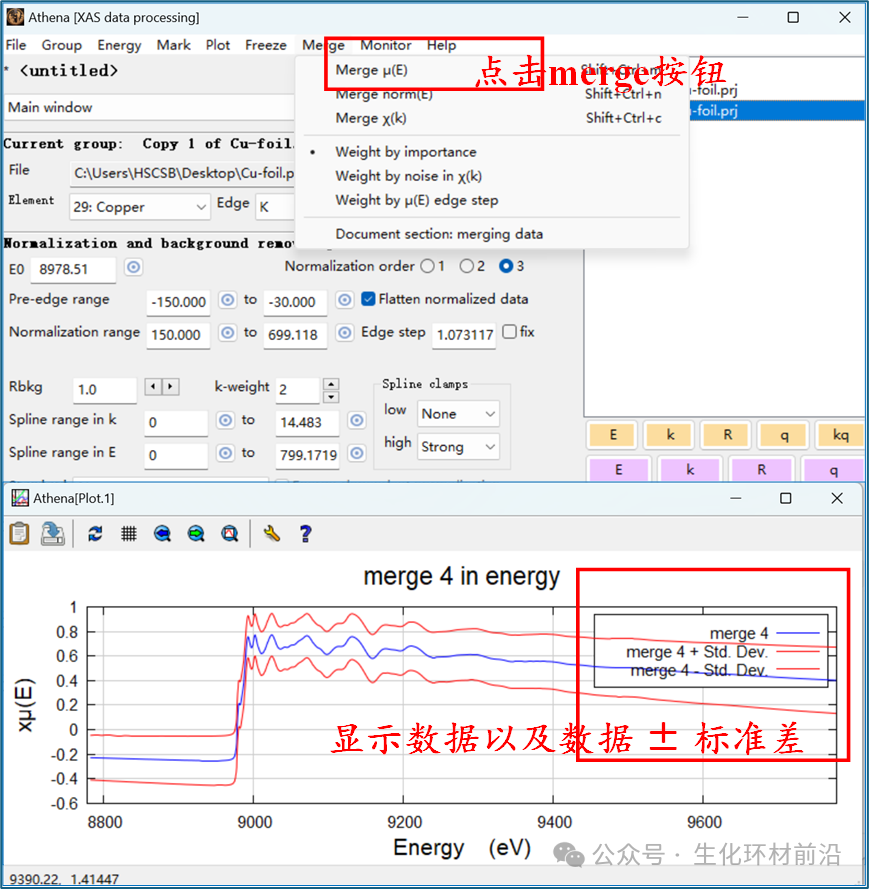
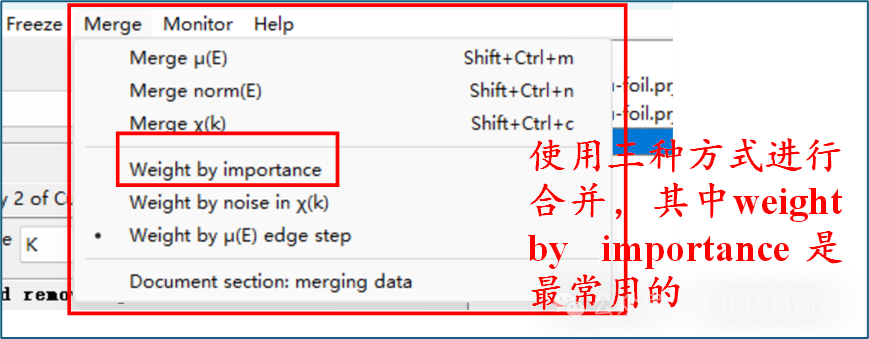
在 Athena 软件中可选择显示方差图、合并图或查看所有合并数据。数据合并是 Athena 的核心功能,通常用于对齐样本扫描图,合并后在 Athena 和 Artemis 中进一步分析处理。 注意:在合并之前,数据必须对齐,否则会严重降低精细结构。 合并光谱的加权方法有三种,如下图所示。默认的“ ipmortance ”参数加权,其中默认值 1 表示同等权重,此外还有“ noise ”选项和“ edge step ”选项。后两者分别给予噪声小和边步长大(即浓度高)的数据更多权重。
Control-shift-n :合并为规一化的 μ(E) 一些光束线允许单色仪在扫描过程中连续旋转,通过以固定速度驱动单色仪并连续读取测量通道来实现。信号在设定的时间段内积分,并在每个时间间隔后存储于缓冲区,最终在扫描结束时转储到磁盘。例如,在 MRCAT 光束线( APS 的第 10 区),典型的 EXAFS 扫描通常在 3 分钟或更短时间内完成。 然而,这种测试模式的缺点是数据采样 过于密集,能量网格通常在 0.3 到 0.5 eV 之间, 这对于 EXAFS 区域来说过于精细,可能导致数据量过大 。
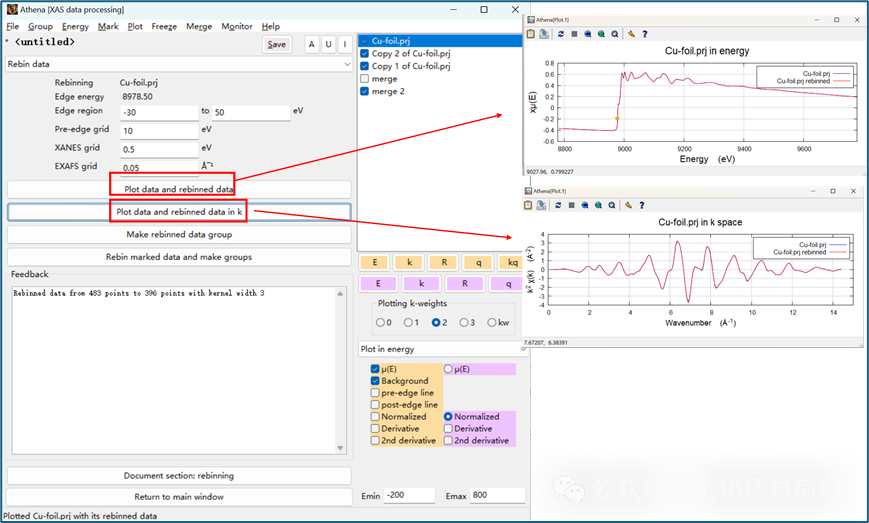
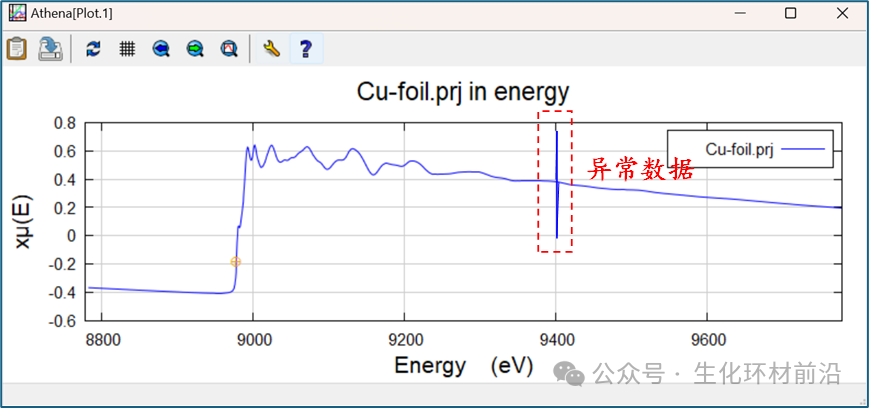
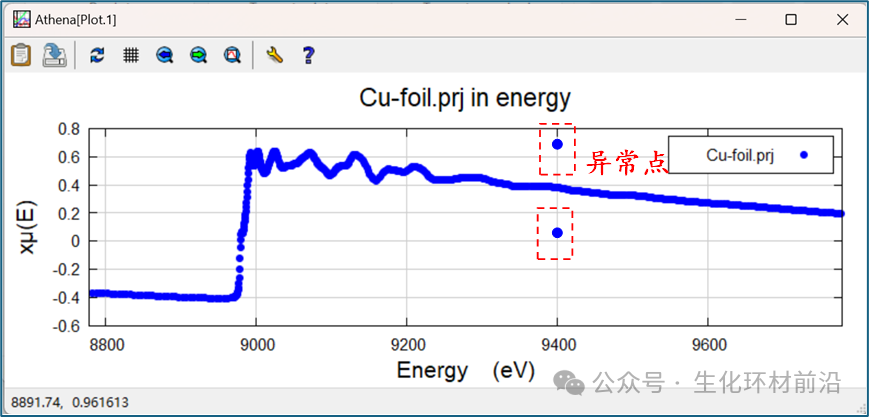
重组工具包含三个区域网格,其中边前区域能量稀疏,吸收边区域能量密集, EXAFS 区域较均匀。 可以在相应的输入框中设置网格大小和边界能量。点击“ Plot ”按钮可查看数据重新分组的结果,“ Plot data ”按钮展示分组的 χ(k) 光谱。通过点击“ Make rebinned data group ”按钮,可以执行重新分组并创建新组,该组将添加到组列表中,允许进一步交互。还可以通过选择多个组并点击“ Rebin ”按钮来批量处理数据,处理时间取决于所选组的数量。 在数据处理中,有时可能会遇到一些与周围数据点明显不同的异常点,这些异常点可能由单色仪、电子设备或样品本身的问题引起。理论上, 少量的异常点对整体数据的影响可以忽略不计,因为它们通常是通过傅立叶变换技术处理的,这些高频信号对数据的影响是很小的。 较大的异常点可能影响数据的美观,还可能对数据的呈现和分析造成干扰。可以通过去毛刺或者截断方式处理数据。 Athena 的去毛刺功能仅移除数据中的异常点,而不进行插值。有两种方法可以去毛刺。
手动去毛刺: 可以通过点击 “Choose a point” 按钮,在数据图中双击异常点,选中后,该点将以橙色圆圈标记。点击 “Remove point” 按钮即可将其从数据中删除。
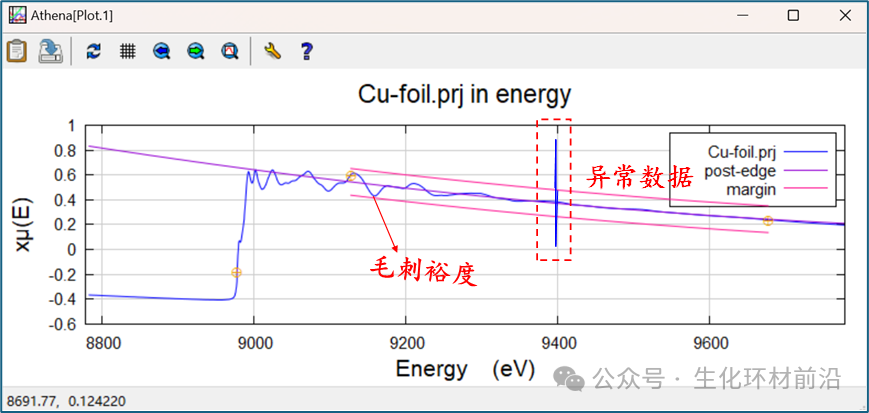
自动化去毛刺: 通过设置去毛刺裕度来识别并移除异常点。这些裕度以粉红色线条显示,在指定的能量范围内,围绕边后线一定距离。裕度的间隔由公差值设定。点击“ Remove glitches ”按钮后,位于上下之外的点将被移除,同样的方法也适用于边前区域。
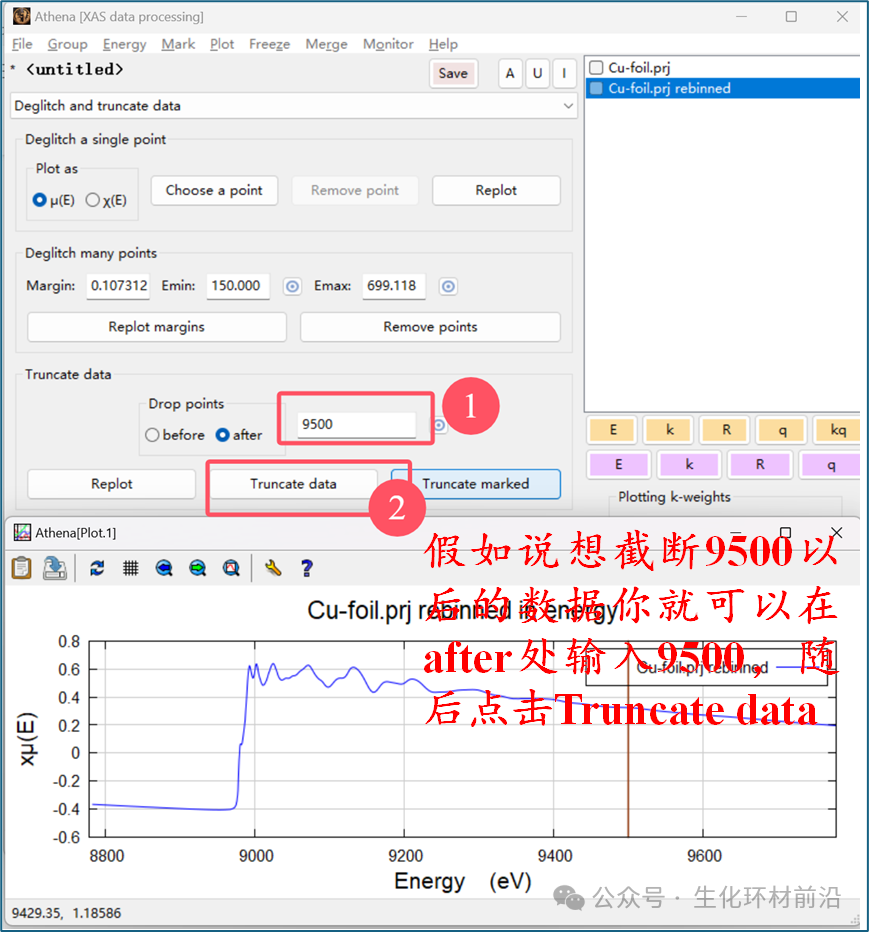
注意:如果裕度设置不当,可能会错误地移除正常数据点,尤其是在白线区域或边后线附近。 如果数据在扫描的某个部分出现异常,可以使用截断工具来去除这部分。通过在单选框中输入或使用弹出按钮来选择截断点。选中相应的单选框后, Athena 将根据选择的截断方向来移除数据。
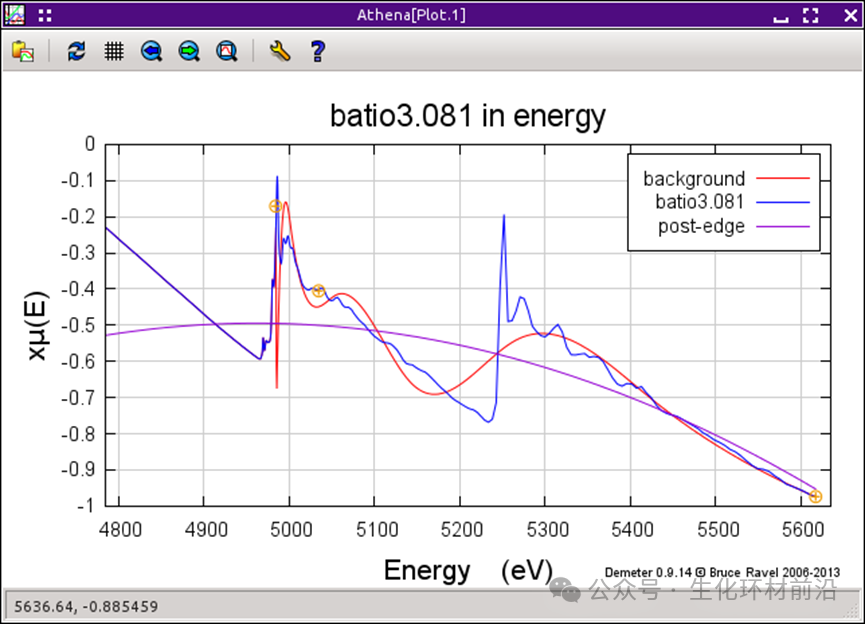
选择特定数据点后,该点将以垂直线的形式标示,如上图所示。要移除该线之前或之后的数据,点击 “Truncate data” 按钮。 有时,数据问题不仅限于某个点之后的数据不可靠。例如,样本中可能含有接近边缘的元素,这限制了可测量数据的范围。下图展示了一个例子,其中 Ti K 边缘位于 4966 eV , Ba L3 边缘位于 5247 eV 。如果对样条和归一化范围选择不当,也可能会导致数据处理上的重大错误。
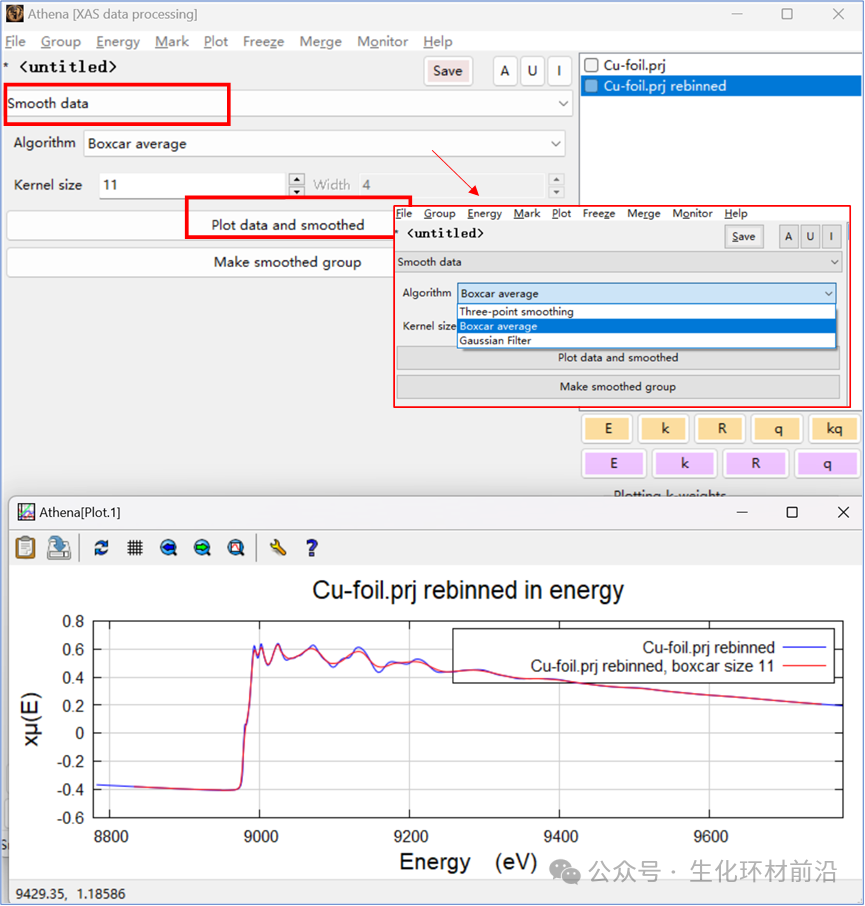
Athena 还有对于噪音数据处理的功能,即平滑数据,但是这种操作并不被推荐!!! 改善噪音数据的最佳方法是尽可能重新考虑样品制备或测试程序。其次,测量更多数据并依靠中心极限定理使数据达到理想化。 Boxcar 平均 : 作为通用线性滤波器,使用指定宽度的平坦对称核,强制使用奇数核大小。 高斯滤波器 : 同样作为通用线性滤波器,需要指定核大小和高斯的 σ 值。 IFEFFIT 三点平滑算法 : 通过重复执行数据来平滑,重复次数由核大小数字控制。
图 5.1 使用 Boxcar 平均对一些嘈杂的氧化金数据进行平滑处理
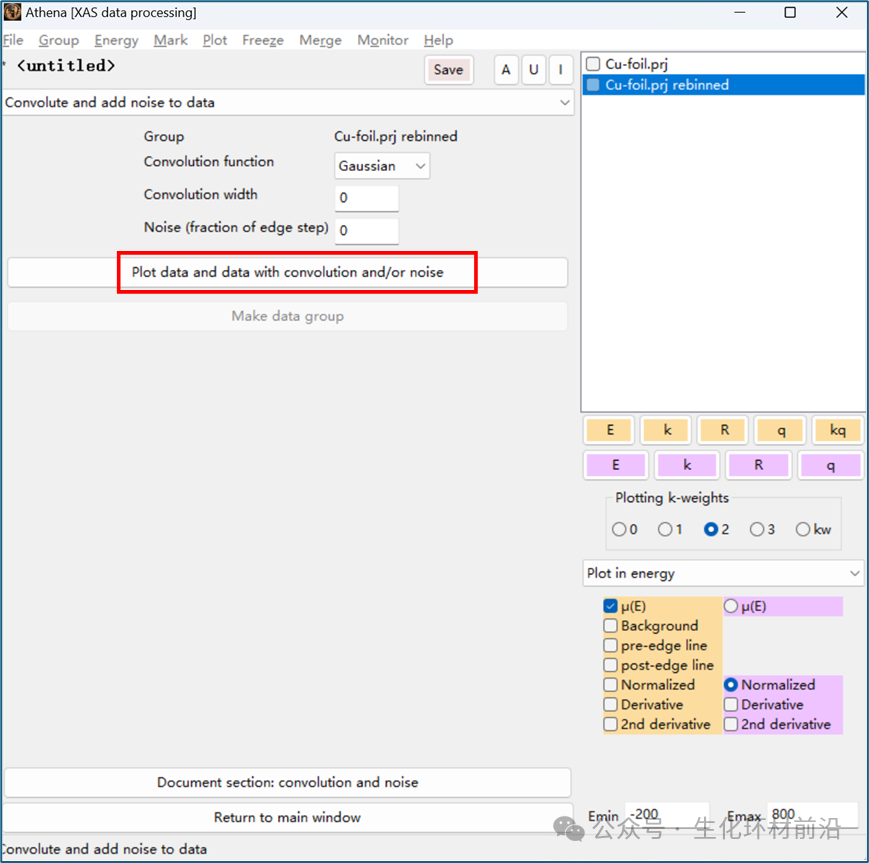
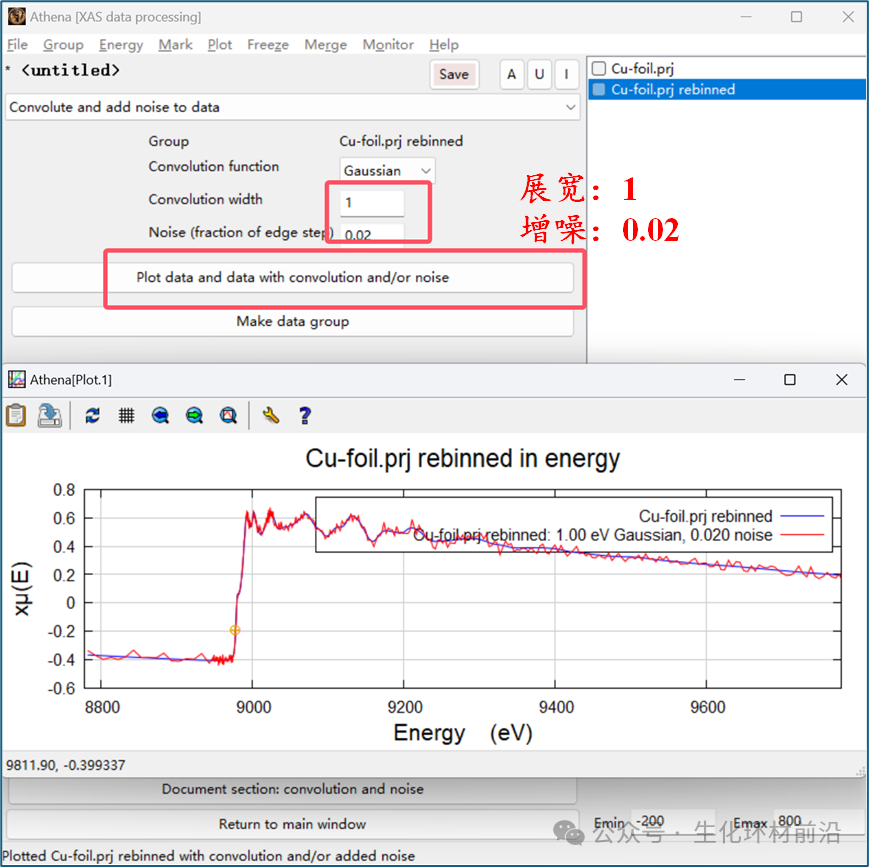
卷积数据是 Athena 比较奇怪的工具。它采用完全精细的归一化 μ(E) 数据,通过添加人工展宽、人工噪音或两者使数据变得更糟。展宽,可以应用高斯或 Lorentzian 卷积,其能量宽度由用户指定。添加噪声可以通过 ε 随机生成, ε 是边步长的一个较小比例。
图 6.1 卷积工具
图 6.2 展宽了 1 eV ,添加 0.02 人工噪音的 Cu foil 数据
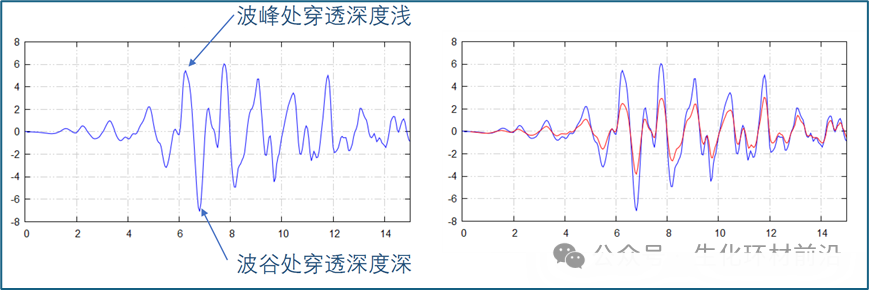
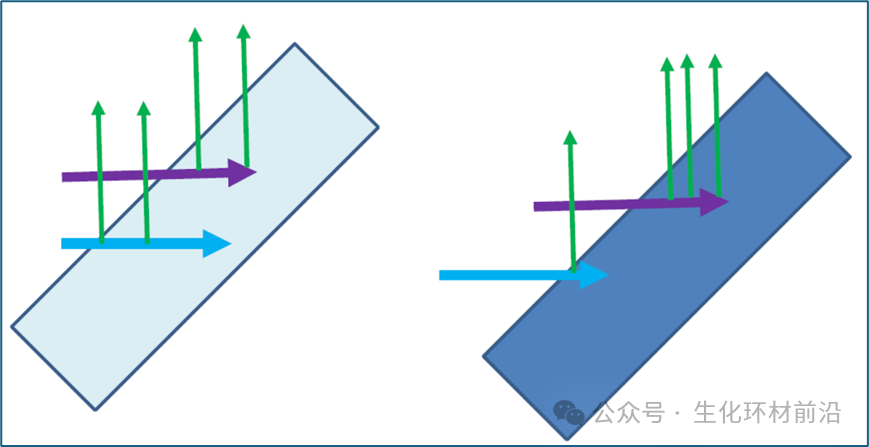
在荧光测量模式下,探测器测量的是入射光激发的二次荧光信号。在震荡信号的波峰位置, X 光穿透深度浅,产生的荧光信号相对减弱;同理,在波谷的位置,产生的荧光信号增强,这样就将震荡信号的强度进行了衰减。
在荧光测量中, μ(E) 通常定义为荧光信号与入射光束信号的比值,但这一定义仅在样品极薄或极稀的情况下准确。对于较厚或较浓的样品, 入射光束的穿透深度会随着 μ(E) 的精细结构变化而变化,导致振荡部分的衰减。 在 X 射线荧光领域, “ 自吸收 ” 一词容易引起混淆,因为它通常指的是荧光在离开样品时的衰减,这与 EXAFS 中讨论的效应不同。在 EXAFS 中,更倾向于使用 “ 过度吸收 ” 或 “ 衰减因子 ” 来描述这一现象。 理想情况下,所有荧光测量的样品都应足够薄或稀,以避免自吸收效应。 如果样品的限制使得自吸收不可避免,就需要在数据分析层面上进行校正。
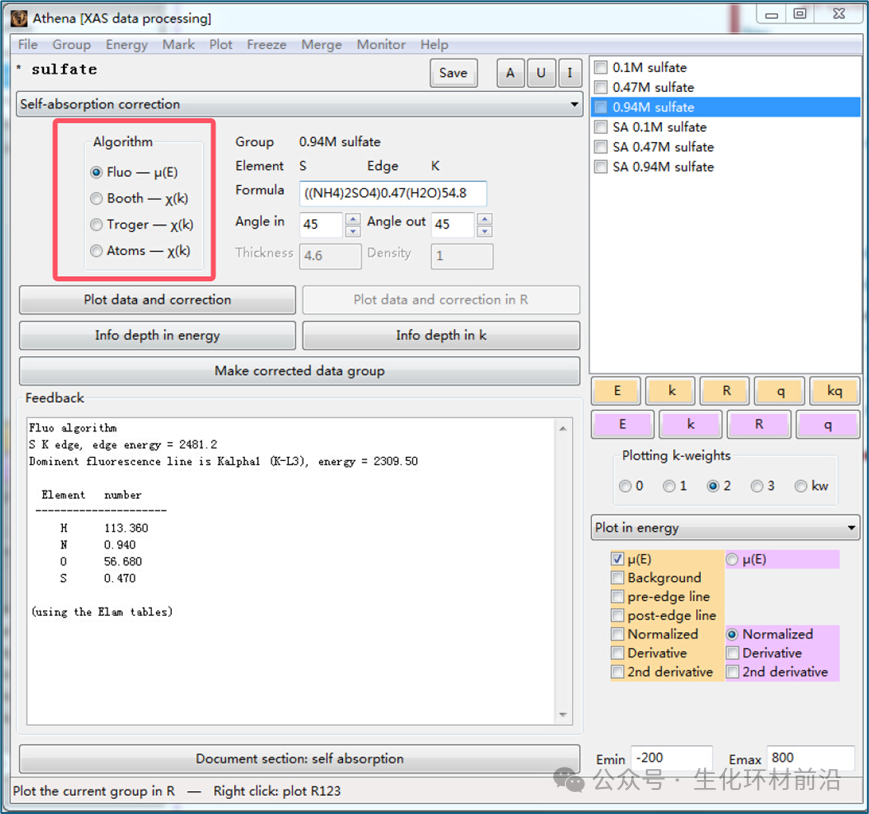
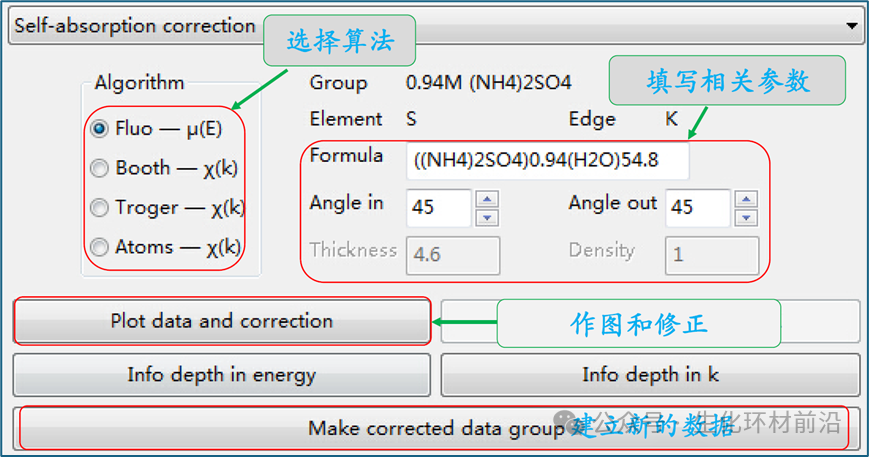
Athena 的自吸收校正工具提供了四种不同的算法,基于 X 射线吸收系数表来近似自吸收的影响,适用于 XANES 和 EXAFS 数据的校正。 注意:自吸收仅影响 EXAFS 数据的振幅,不影响相位,因此即使无法完全校正,仍可分析键长信息。自吸收校正的成功率很难保证,尤其是当样品成分未知时,校正可能不可靠。
在这个校正 XANES 数据的示例中,硫酸铵以三种不同的摩尔浓度溶解在水中: 0.1 、 0.74 和 0.94 。校正算法需要了解样品细节,因此需要计算出水与硫酸铵的比例。
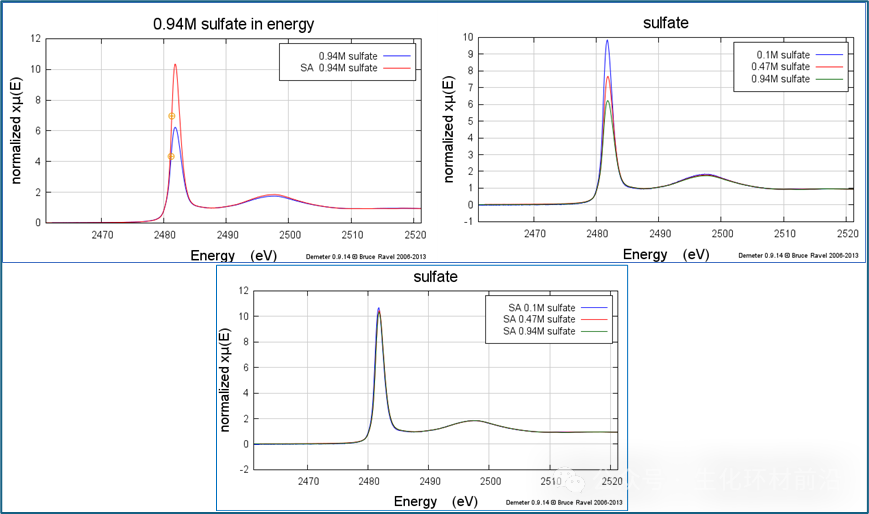
调整添加溶质后的密度变化后,溶液中约有 54.8 mol 水。因此,这三种摩尔溶液的公式分别为 ((NH4 )2 SO4 )0.10 (H2 O)54.8 、 ((NH4 )2 SO4 )0.47 (H2 O)54.8 和 ((NH4 )2 SO4 )0.94 (H2 O)54.8 。 左侧显示了 0.94M 样本的未校正和校正数据,右侧显示了三个未校正光谱,底部显示了校正光谱。
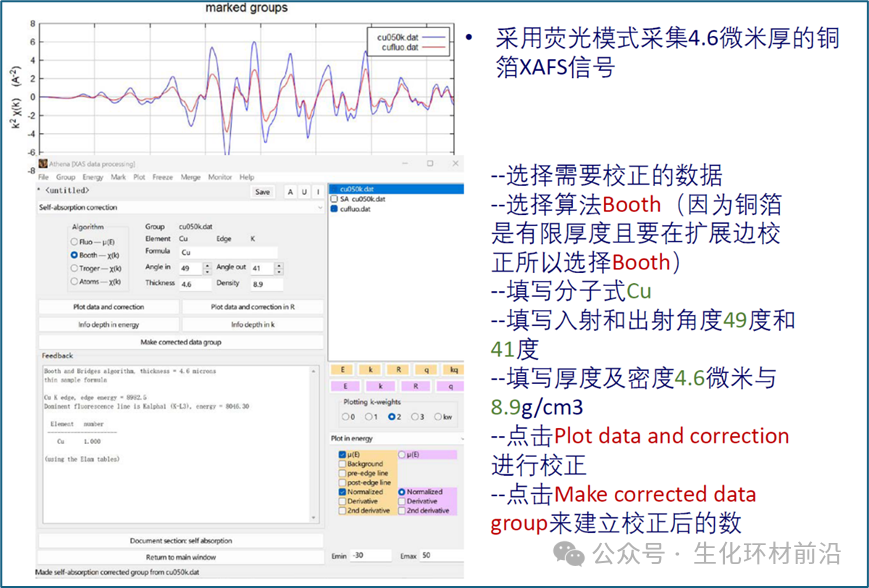
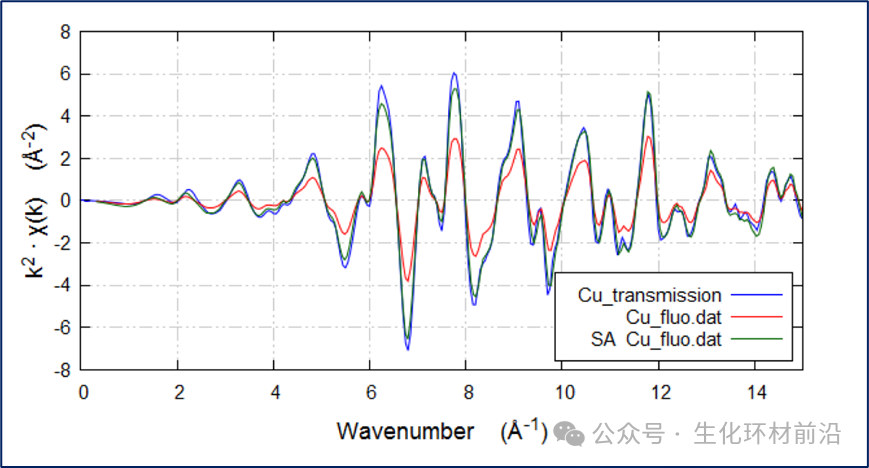
四种算法中,只有如下图所示的 Booth 算法适合有限厚度的样品,其余三种算法均假设样品为无限厚。 图 7.7 使用 Booth 算法对铜数据进行校正的自吸收工具 由于这是薄膜,因此只有 Booth 算法才适用。 选择算法后,可以使用其他控件输入入射角和出射角、样品厚度和密度。所有算法都以原子百分比的化学计量法指定样品的公式。 铜的化学式为 Cu , Corwin 报告称样品厚度为 4.6 ,入射角为 49 度,出射角为 41 度。输入这些值并绘制校正图。保存校正后的数据组并将其与透射数据进行比较,绿色曲线是校正后的荧光光谱,与透射数据相比效果很好, 如下图所示。
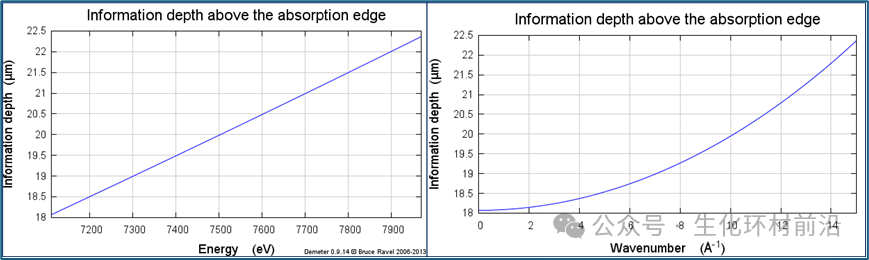
信息深度是一个由 Troger 等人定义的重要参数,它描述了在特定样品几何和能量条件下,入射光束探测到的样品深度。在这个深度上,大约 68% 的入射光子被吸收,同时产生 68% 的荧光光子。信息深度是评估薄膜样品在实验中是否可以被视为 “ 厚 ” 的一个有用指标,并且对于任何样品,都可以绘制信息深度与波数的关系图。
图 7.9 以能量绘制的铁 / 镓合金的信息深度
(图片来源: https://bruceravel.github.io/demeter/documents/Athena/process/sa.html)
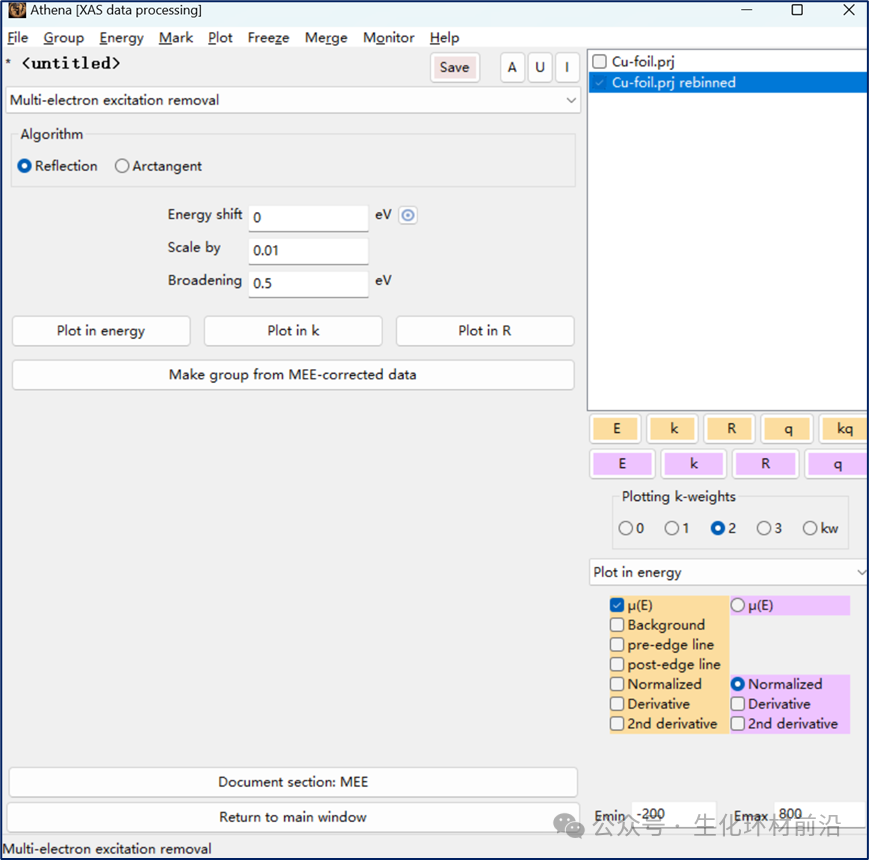
Fluo 的程序文档可以在 Dani 的网站上找到,其中包括数学推导: http://www.aps.anl.gov/haskel/fluo.htmlC H Booth 和 F Bridges 。扩展 X 射线吸收精细结构荧光测量的改进自吸收校正。 Physica Scripta , 2005(T115):202 , 2005 年。 doi:10.1238/Physica.Topical.115a00202 。 另请参阅 Corwin 的网站: http://lise.lbl.gov/RSXAP/ L. Tröger 、 D. Arvanitis 、 K. Baberschke 、 H. Michaelis 、 U. Grimm 和 E. Zschech 。软荧光扩展 X 射线吸收精细结构中自吸收的完全校正。 Phys. Rev. B , 46:3283–3289 , 1992 年 8 月。 doi:10.1103/PhysRevB.46.3283 。 P. Pfalzer 、 J.-P. Urbach 、 M. Klemm 、 S. Horn 、 Marten L. denBoer 、 Anatoly I. Frenkel 和 J. P. Kirkland 。荧光硬 X 射线吸收光谱中自吸收的消除。 Phys. , 60:9335–9339 , 1999 年 10 月。 doi:10.1103/PhysRevB.60.9335 。 Bruce Ravel 。《原子: X 射线吸收光谱学家的晶体学》。《同步辐射杂志》, 8(2):314–316 , 2001 年 3 月。 doi:10.1107/S090904950001493X 。 有关荧光校正计算的更多详细信息,另请参阅 Bruce 网站上的 Atoms 文档。 W. T. Elam 、 B. D. Ravel 和 J. R. Sieber 。用于 X 射线光谱计算的新型原子数据库。辐射物理与化学, 63:121–128 , 2002 年 2 月。 doi:10.1016/S0969-806X(01)00227-4 。 XAS 通常被视为单电子过程,即一个光子激发出一个光电子。然而,实际上也可能发生多电子激发, 这在解释 XAS 数据时有时必须予以考虑。其中一种现象是 “ 甩离 ” 效应,光电子具有足够的动能去激发其他高能电子。例如,在铀的 L3 边上方约 415 eV 处,光电子能够激发 N6 或 N7 电子跃迁。 这种次级跃迁的横截面积可能非常小,如在 L3 N6,7 跃迁的例子中,次级横截面比初级 L3 边小约三个数量级。如果数据质量高,并且可测量的 EXAFS 超过约 10.5 Å-1 ,那么多电子激发的影响将不容忽视。 另一个可能影响数据的现象是 Z+1 元素的微量杂质,这可能导致测量边上方出现小的跳高。 在某些情况下,这些小台阶在 μ(E) 数据中可能难以察觉,但在 χ(k) 中可能表现为明显的台阶,傅里叶变换后在 χ(R) 光谱的低 R 区域产生贡献。 为了解决这一问题, Athena 提供了两种算法来尝试消除多电子激发或数据中的噪音导致的跳高影响。一种算法通过建立一个模型来模拟这种多电子激发过程,将其作为激发能量位置的一个函数来处理;另一种算法通过在特定能量位置应用反正切函数,可以减少或消除由噪音引起的跳高对整体光谱的影响。 注意:这里描述的算法需要用户足够的知识才能合理处理数据。在任何情况下结果都不会完美。请谨慎使用此工具!
点击“ Make series ”按钮,将基于当前数据组创建一系列副本,其中被检查的参数会逐步递增。这些副本组将被标记,并在最适合观察该参数影响的图表中显示。
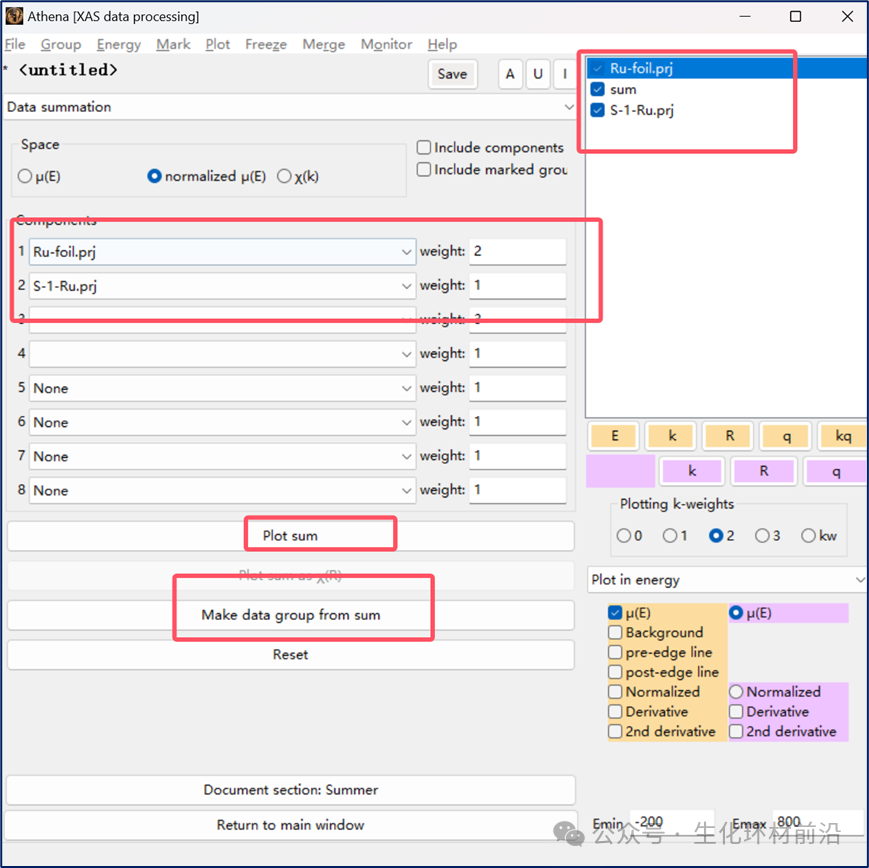
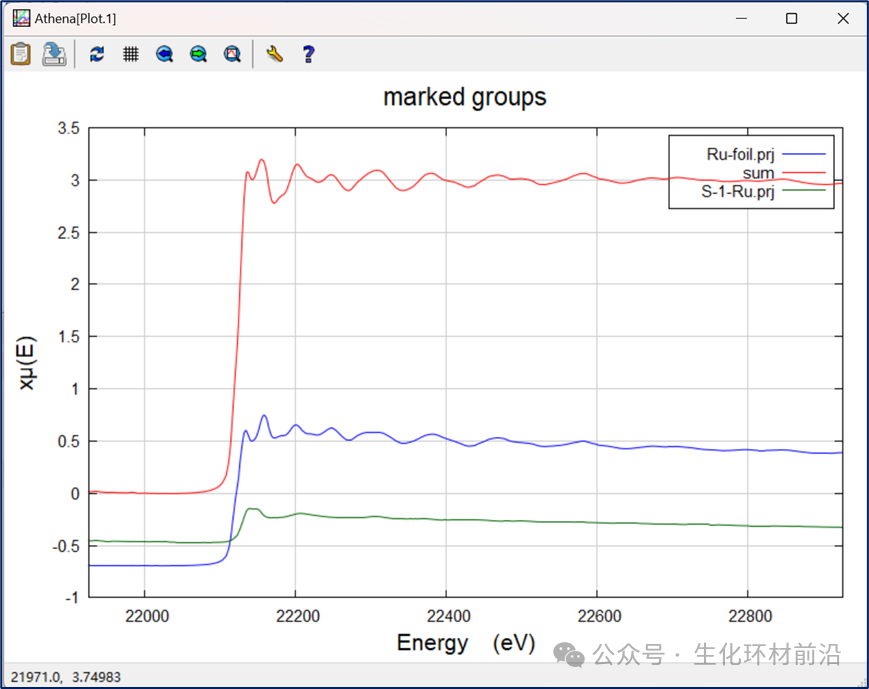
数据汇总工具结合了线性组合拟合和差谱工具的特点,但又有其独特之处。可以对μ (E) 、归一化的 μ(E) 或 χ(k) 数据进行任意加权求和,其中权重可以是任意数值,不要求为正数或总和为 1 。在绘图时,可以选择是否包含缩放的分量或组列表中特定标记的组。如果对 χ(k) 数据进行求和,还可以选择将结果绘制为 χ(R) 。
是指在一定条件下,即使单个随机变量不服从正态分布,只要这些变量是独立同分布且具有有限的均值和方差,当样本量足够大时,这些变量的总和或平均值的分布将趋近于正态分布。
在 EXAFS 测试的背景下,如果噪音主要是由统计噪音引起的,那么噪音频谱将在其均值附近呈正态分布。 如果我们测量了足够多的数据,并且以统计噪音为主,通过计算每个能量点的算术平均值来合并数据,那么数据将趋于收敛到其真实平均值。 回归到我们科研中亦是如此,我们经常面临实验结果的不稳定性。例如,制备的催化剂活性时而优异,时而表现不佳,有时甚至无法重复出一致的结果。但是,只要我们有足够的耐心和进行大量的重复实验,即使是杂乱无章的数据也可以变得规律有序。加油科研人!!
声明:如需转载请注明出处(华算科技旗下资讯学习网站-学术资讯),并附有原文链接,谢谢!