

Larch 是一个开源的 Python 库和应用程序套件,专门用于处理和分析同步加速器光束线上的 X 射线吸收和荧光光谱数据以及 X 射线荧光和衍射图像。它提供了全面的 XAFS 分析工具,包括 XANES 和 EXAFS,以及 XRF 和 XRD 图像的可视化工具。


Larch 依赖于多个科学 Python 库,并提供了 GUI 应用程序,如 Larix 和 GSE Map Viewer,以及一个类似 Python 的宏语言,用于交互式和批处理分析。
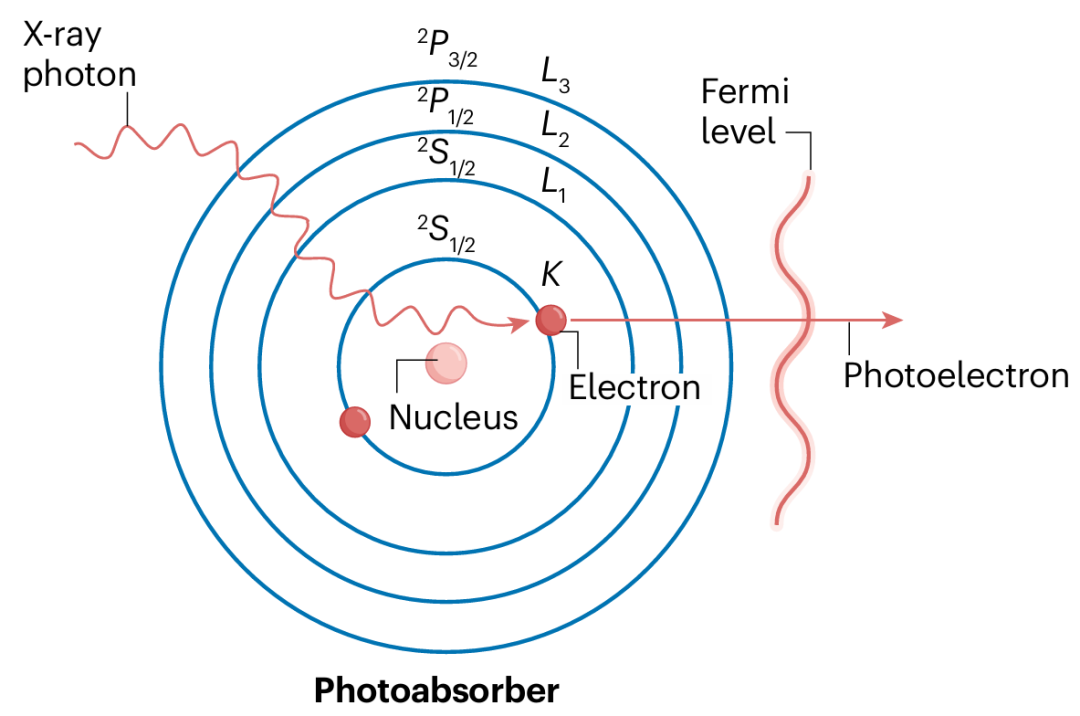
它支持从 GUI 分析到脚本和批处理分析的过渡,并可作为后台服务运行,与其他应用程序如 Demeter 集成。本文将主要介绍Larch处理XAS时常用的数据组及命名。
Larch 提供了一系列与它一起安装的应用程序,包括图形用户界面(GUI)和命令行界面(CLI),以及一些处于测试阶段(beta)的工具。
此外,它还包含了 Feff6L 和 Feff8L 代码,这是 Feff 项目的开源版本,由 Larch 获得许可并重新分发,以支持 X 射线光谱分析。
与多数Larch函数一致,XAFS函数均支持对任意数据数组进行操作,以实现数据处理的最大灵活性。同时,不少Larch XAFS函数可输出标量、数组等多类结果。尽管灵活性突出,但这种设计不仅操作繁琐,还要求用户频繁跟踪大量关联数组。
3.1 XAFS 数组的命名
在 Larch 中,将相关数据归入一个 “组” 是最自然的处理方式 —— 从文件读取的数据本就默认保存在组内。若 XAFS 数据存于组中,组内名为 energy、k、chi ,对所有 XAFS 数据组而言具有统一的标准含义。
为简化这一最常用场景,所有 XAFS 函数均遵循特定约定:既保留对任意数据数组的处理能力,又默认将输出值写入组内;多数情况下,只需为 XAFS 函数指定一个符合预期命名规则的组即可。
这一约定并非强制,组内也可添加其他名称的数据,但遵循规则能大幅降低 XAFS 数据的处理难度。
所谓命名约定,即定义了组内数据数组与标量的一套预期名称及对应含义,具体内容汇总于下方的“XAFS 组约定名称表”。
XAFS 群的常规名称表:这些是与 XAFS 相关的各种数据(包括 FEFF 计算)的数组和标量的标准名称。表中给出了名称、描述的物理量以及生成该值的函数名称。
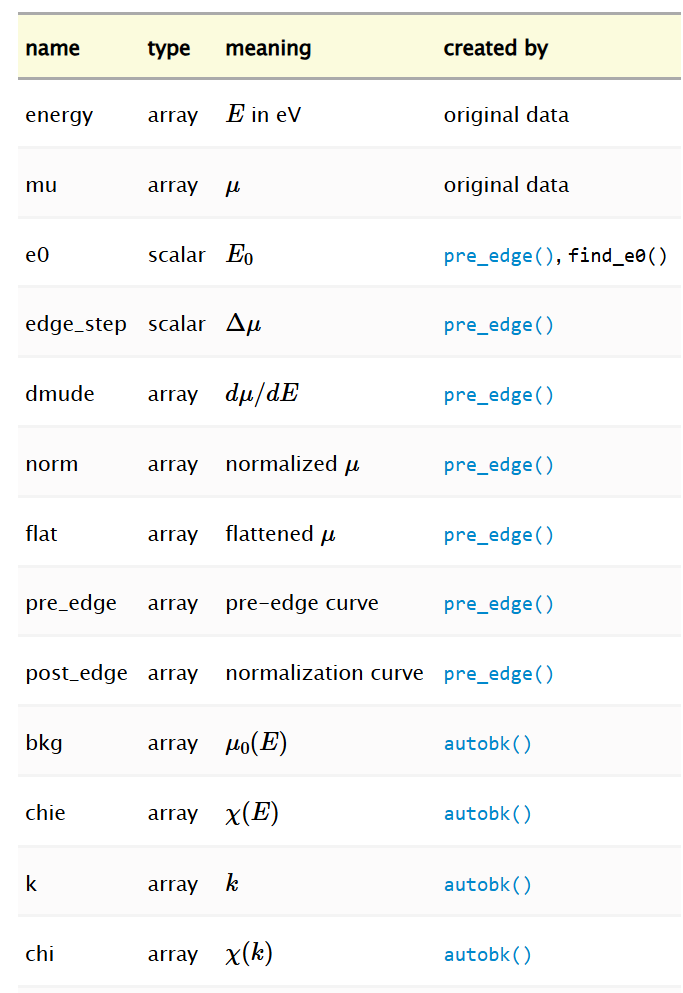

XAFS 函数遵循这一规定,因为它们始终希望由两个数组表示:GROUP.k和GROUP.chi。
3.2组参数和_sys. xafs Group
XAFS 函数输出量较大,需指定写入的组来管理。为此,所有函数均支持通过“组参数” 指定结果写入的组,这虽为不同分析步骤的结果管理提供了便捷,但处理特定数据集时重复输入该参数会十分繁琐。
针对 XAFS 分析,存在一个特殊组_sys. xafs Group:若未提供显式组参数,它将作为默认组接收输出;若指定了显式组参数,它会自动设为该组。
简言之,_sys. xafs Group即 “当前默认组”—— 当 XAFS 数据包含在单个组中(常规场景),无需重复输入组参数。
需注意,该约定依赖 Larch 解释器的全局组,因此仅适用于 Larch 语言;若在纯 Python 中使用,需通过_larch参数传递 Larch 会话实例至larch. xafs函数,方可适用。
3.3第一个参数组约定
由于 XAFS 函数需将输出写入组中,且通常处理的组包含符合 XAFS 组约定名称表的数据,因此多数 XAFS 函数遵循 “第一个参数组约定“。
该约定基于前文所述的_sys. xafs Group约定,为处理 XAFS 数据组提供了更便捷的方式,是大多数 XAFS 工作中需理解和运用的重要规则。
尽管 XAFS 函数可接受数据数组作为前两个参数,但多数情况下,这些数组会按上述约定命名并置于同一组中。例如,autobk ()函数最常见的用法是:将能量数组作为第一个参数,mu 数组作为第二个参数,并指定一个输出组来存放函数计算的所有数组和数据。
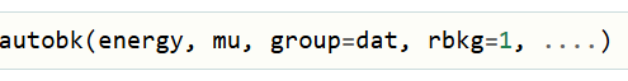
当然,大多数情况下,我们实际上会希望使用同一组中的energy和mu数组,并将该组用作输出组,这样所有数据都会保留在同一组中。这样,上面的调用看起来会像这样:

其中组名数据重复了三次。
第一个参数组约定允许将其写为:

也就是说,只要 Group数据遵循 XAFS 命名约定(例如,它有一个名为energy autobk()的能量数组和一个名为mu的吸光度数组),上述两种形式就是等效的。所有 XAFS 函数都遵循此约定,并使用一组一致的属性名称。
此约定几乎使 Larch XAFS 例程成为面向对象的函数集,这些函数集以一致且可预测的方式在 XAFS 数据集上进行交互。
3.4为 XAFS 绘制宏
XAFS分析通常使用数据阵列的几种不同标准视图来μ(E),χ(K)和χ(R)Larch的绘图功能为绘图方式提供了极大的灵活性。虽然这种灵活性通常很有用,但在绘制 XAFS 数据这一特定领域,能够使用合理的默认值轻松创建一致的绘图,可以生成更易于理解的结果。
这里描述的宏试图提供易于使用的标准绘图宏的功能。具体来说,它们能够自动以一致的方式排版绘图轴的标签,并为显示的不同曲线分配一致的标签。这些宏也易于扩展,以便可以添加曲线、注释等。
plot_mu()
plot_mu( dgroup , norm = False , deriv = False , show_pre = False , show_post = False , show_e0 = False , emin = None , emax = None , label = None , new = True , win = 1 )
绘制各种形式的 XAFS 数据组
参数:
dgroup – pre_edge()后的 XAFS 数据组
norm –是否显示标准化数据 [ False]
deriv –是否显示 XAFS 数据的导数 [ False]
show_pre –是否显示预边缘曲线 [ False]
show_post –是否显示后边缘曲线 [ False]
show_e0 –是否显示 E0 [ False]
show_deriv –是否将 deriv 与 mu [ False]一起显示
emin – 显示的最小能量,相对于 E0 [ None,数据开始]
emax – 相对于 E0 的最大显示能量 [ None,数据结束]
label – 标签字符串[ None:‘mu’、‘dmu/dE’ 或 ‘mu norm’]
new –是否开始新绘图 [ True]
win – 要使用的整数绘图窗口 [1]
输入数据组必须具有以下属性:energy、mu、norm、e0、pre_edge、edge_step、filename。
plot_bkg()
plot_bkg( dgroup , norm = True , emin = None , emax = None , show_e0 = False , label = None , new = True , win = 1 )
绘制和背景对于XAFS数据组
参数:
dgroup – autobk() 后的 XAFS 数据组
norm –是否显示标准化数据 [ True]
emin – 显示的最小能量,相对于[ None,数据开始]
emax – 相对于显示的最大能量[ None,数据结束]
show_e0 –是否显示 E0 [ False]
label – 标签字符串[ None:’mu’]
new –是否开始新绘图 [ True]
win – 要使用的整数绘图窗口 [1]
输入数据组必须具有以下属性:energy、mu、bkg、norm、e0、pre_edge、edge_step、filename 。
plot_chik()
plot_chik( dgroup , kweight = None , kmax = None , show_window = True , label = None , new = True , win = 1 )
绘制 k 加权图对于XAFS数据组
参数:
dgroup – autobk()后的 XAFS 数据组
kweight – 绘图的 k 权重 [从最后一个读取xftf(),或 0]
kmax – 要显示的最大 k [ None,数据结束]
show_window – bool 是否也绘制 k-window [ True]
label – 标签字符串[ None:’chi’]
new – bool 是否开始新绘图 [ True]
win – 要使用的整数绘图窗口 [1]
输入数据组必须具有以下属性:k、chi、kwin、filename。
14.1.2.4.plot_chir()
plot_chir( dgroup , show_mag = True , show_real = False , show_imag = False , rmax = None , label = True , new = True , win = 1 )
绘制对于XAFS数据组
参数:
dgroup – xftf()后的 XAFS 数据组
show_mag – bool 是否绘图[ True]
show_real – bool 是否绘图[ False]
show_imag – bool 是否绘图[ False]
rmax – 显示的最大 R [ None,数据结束]
label – 标签字符串[ None:’chir’]
new – bool 是否开始新绘图 [ True]
win – 要使用的整数绘图窗口 [1]
输入数据组必须具有以下属性:r、chir_mag、chir_im、chir_re、kweight、filename
14.1.2.5.plot_chifit()
plot_chifit(数据集, kmin = 0 , kmax = None , rmax = None , show_mag = True , show_real = False , show_imag = False , new = True , win = 1 )
绘制 k 加权图和适合 feffit 数据集
参数:
数据集– feffit 数据集,运行后feffit()。
kmin – 最小 k 显示 [0]
kmax – 要显示的最大 k [ None,数据结束]
rmax – 显示的最大 R [ None,数据结束]
show_mag – bool 是否绘图[ True]
show_real – bool 是否绘图[ False]
show_imag – bool 是否绘图[ False]
new – bool 是否开始新绘图 [ True]
win – 要使用的整数绘图窗口 [1]
plot_path_k()
plot_path_k(数据集, ipath, kmin = 0, kmax = None, offset = 0,标签= None, new = False, win = 1, ** kws )
绘制 k 加权图对于 feffit 数据集的单个路径
参数:
数据集– feffit 数据集,运行后feffit()
ipath – 路径索引,起始计数为 0 [0]
kmin – 最小 k 显示 [0]
kmax – 要显示的最大 k [ None,数据结束]
offset – 用于绘图的垂直偏移 [0]
label – 路径标签 [‘路径 I’]
new –是否开始新绘图 [ True]
win – 要使用的整数绘图窗口 [1]
kws – 附加关键字参数传递给 plot()
plot_path_r()
plot_path_r(数据集, ipath, rmax = None,偏移量= 0,标签= None, show_mag = True, show_real = False, show_imag = True, new = False, win = 1, ** kws )
绘制对于 feffit 数据集的单个路径
参数:
数据集– feffit 数据集,运行后feffit()
ipath – 路径索引,起始计数为 0 [0]
kmax – 显示的最大 k [无,数据结束]
offset – 用于绘图的垂直偏移 [0]
label – 路径标签 [‘路径 I’]
show_mag – bool 是否绘图[ True]
show_real – bool 是否绘图[ False]
show_imag – bool 是否绘图[ False]
new – bool 是否开始新绘图 [ True]
win – 要使用的整数绘图窗口 [1]
kws – 附加关键字参数传递给 plot()
plot_paths_k()
plot_paths_k(数据集,偏移量=-1,kmin=0, kmax=None, new=True, win=1, kws):
绘制模型的 k 加权卡方图 (k)和 feffit 数据集的所有路径
参数:
数据集– feffit 数据集,运行后feffit()
kmin – 最小 k 显示 [0]
kmax – 要显示的最大 k [ None,数据结束]
offset – 绘图路径使用的垂直偏移量[-1]
new –是否开始新绘图 [ True]
win – 要使用的整数绘图窗口 [1]
kws – 附加关键字参数传递给 plot()
plot_paths_r()
plot_paths_r(数据集,偏移量=-0.5, rmax=None, show_mag=True, show_real=False, show_imag=False, new=True, win=1, kws):
绘制对于模型和 feffit 数据集的所有路径
参数:
数据集– feffit 数据集,运行 func: feffit后
offset – 绘图路径的垂直偏移量[-0.5]
rmax – 显示的最大 R [ None,数据结束]
show_mag –是否绘图[T“rue“]
show_real –是否绘图[ False]
show_imag –是否绘图[ False]
new –是否开始新绘图 [ True]
win – 要使用的整数绘图窗口 [1]
kws – 附加关键字参数传递给 plot()
plot_prepeaks_baseline()
plot_prepeaks_baseline(dgroup,subtract_baseline=False, show_fitrange=True, show_peakrange=True, win=1, **kws):
绘制前边缘峰和基线拟合,如来自pre_edge_baseline()或 Larix。
参数:
dgroup – 数据组,运行后pre_edge_baseline()
subtract_baseline – bool 是否减去绘图基线
show_fitrange – bool 是否将适合范围显示为垂直条
show_peakrange – bool 是否显示带有标记的预边缘峰值范围
win – 要使用的整数绘图窗口 [1]
kws – 附加关键字参数传递给 plot()
dgroup组必须有一个prepeaks子组。
plot_prepeaks_fit()
plot_prepeaks_fit(dgroup,show_init=False, subtract_baseline=False, show_residual=False, win=1, **kws):
绘制边缘前峰值并进行拟合,就像在 Larix GUI 中一样
参数:
dgroup – 运行预边缘峰值拟合后的数据组。
show_init – bool 是否在拟合之前显示初始模型
subtract_baseline – bool 是否减去绘图基线
show_residual – bool 是否将残差显示为堆积图。
win – 要使用的整数绘图窗口 [1]
kws – 附加关键字参数传递给 plot()
dgroup组必须包含一个peakfit_history子组。目前,该子组只能通过 Larix GUI 或由其编写(可能经过修改)的脚本自动生成。
这里列出了 XAFS 的一些通用函数。
ktoe()和etok()
etok(能量)
将光电子能量(单位:eV)转换为波数(单位:Å-1. 能量可以是单个数字或数字数组。
ktoe(波数)
将光电子波数转换为Å-1以 eV 为单位的能量。波数可以是单个数字或数字数组。
以下是能量表和值:
estimate_noise()
估计噪声(k,chi=无, group=无, rmin=15, rmax=30, ….)
自动估算噪声水平光谱。
参数:
k – 一维数组
chi – 一维数组
组——输出组。
rmin – 最小值噪声估计值。
rmax – 最大值噪声估计值。
kweight – k**kweight 加权谱的指数 [1]
kmin – FT 窗口的起始 k [0]
kmax – FT 窗口的结尾为 k [20]
dk – FT 窗口的锥度参数[4]
dk2 – FT 窗口的第二个锥度参数[无]
window – 窗口类型的名称 [‘kaiser’]
nfft – 用于 N_fft [2048] 的值。
kstep – 用于 delta_k 的值 ( Ang^-1 ) [0.05]
该方法使用 XAFS 傅里叶变换,并且的许多参数(kmin、kmax等)与的相同xftf()。
此函数遵循“第一个参数组”约定,数组名为k和chi。以下输出将写入提供的组(如果未提供组,则写入_sys.xafsGroup )

该方法以 rmin 与 rmax 区间的数据测量噪声水平,通过 Parseval 定理将其转换,并隐含两个假设:频谱的高 R 部分无信号,且噪声为 “白噪声“。
这些假设虽均有可质疑之处,但要否定它们并忽略此处的噪声估计,需具备 XAFS 光谱噪声的专业知识,而多数用户并不具备。因此,该估计至少应被视为噪声水平的最小下限。
输出值 kmax_suggest 的估计偏保守,虽可能夸大噪声影响,但能客观反映数据质量。对于优质数据,这种保守性尤为明显;不过考虑到实际值可能更小,该估计也并非严重失当。
【高端测试 找华算】
华算科技是专业的科研解决方案服务商,精于高端测试。拥有10余年球差电镜拍摄经验与同步辐射三代光源全球机时,500+博士/博士后团队护航,保质保量!
?已助力5️⃣0️⃣0️⃣0️⃣0️⃣➕篇科研成果在Nature&Science正刊及子刊、Angew、AFM、JACS等顶级期刊发表!
?立即预约,抢占发表先机!