

本文全面探讨了分子力场这一计算化学的核心工具如何描述原子间相互作用并推动分子模拟。
从力场的基本概念、功能形式和参数化挑战入手,详细介绍了传统加和性力场(如AMBER、CHARMM)及其局限性。深入分析了旨在克服这些局限的第二代力场,包括可极化力场、反应力场以及混合量子力学/分子力学(QM/MM)方法。
机器学习力场作为前沿进展,它们结合了量子力学精度与分子力学效率,并在药物发现、材料科学和生物分子模拟等领域展现出巨大潜力。最后,本文展望了力场发展的未来趋势,包括人工智能的深度融合和通用力场的突破,以及计算化学面临的挑战与机遇。
力场的基本概念
定义与作用
分子力场是计算化学、分子物理和分子建模领域中的一种计算模型,其核心功能在于描述原子(或原子集合)在分子内部、分子之间以及晶体结构中的相互作用力。这些力场本质上是一类原子间势能函数,其目标是根据原子坐标计算体系的势能,从而能够在无需昂贵实验的情况下,研究分子的结构、行为和动力学特性。
力场是分子力学(MM)方法的基础,MM是一种经典近似方法,它忽略了电子的运动,仅根据原子核的位置来计算体系能量。这种处理方式赋予了MM力场相对于量子力学(QM)方法显著的计算效率优势,尤其适用于包含大量原子的复杂体系 。
尽管MM力场在某些性质的计算上可以达到与高水平QM计算相媲美的精度,但它无法直接提供依赖于电子分布的性质,例如电荷转移或化学反应的详细电子机制 。
体系中每个粒子所受的力,都是通过势能函数对粒子坐标的梯度来导出的,这与经典物理中力场的概念相呼应,但其作用尺度聚焦于原子层面。分子力场主要应用于分子动力学(MD)和蒙特卡洛(MC)模拟,以揭示分子随时间的动态行为 。
计算化学领域存在一个核心的权衡:精度与效率。量子力学方法提供了高精度,但计算成本极高,限制了其在大体系和长时尺度模拟中的应用。分子力学力场正是为了解决这一问题而生,它通过牺牲量子层面的电子细节,换取了计算效率的显著提升。
这种权衡决定了MM力场在生物分子动力学等领域不可或缺的地位,使其成为模拟大体系和长时尺度的唯一可行选择 。这种根本性的权衡也推动了更先进力场(如可极化力场、反应力场、机器学习力场)和混合方法(如QM/MM)的持续发展,以期在保持效率的同时弥补精度上的差距。
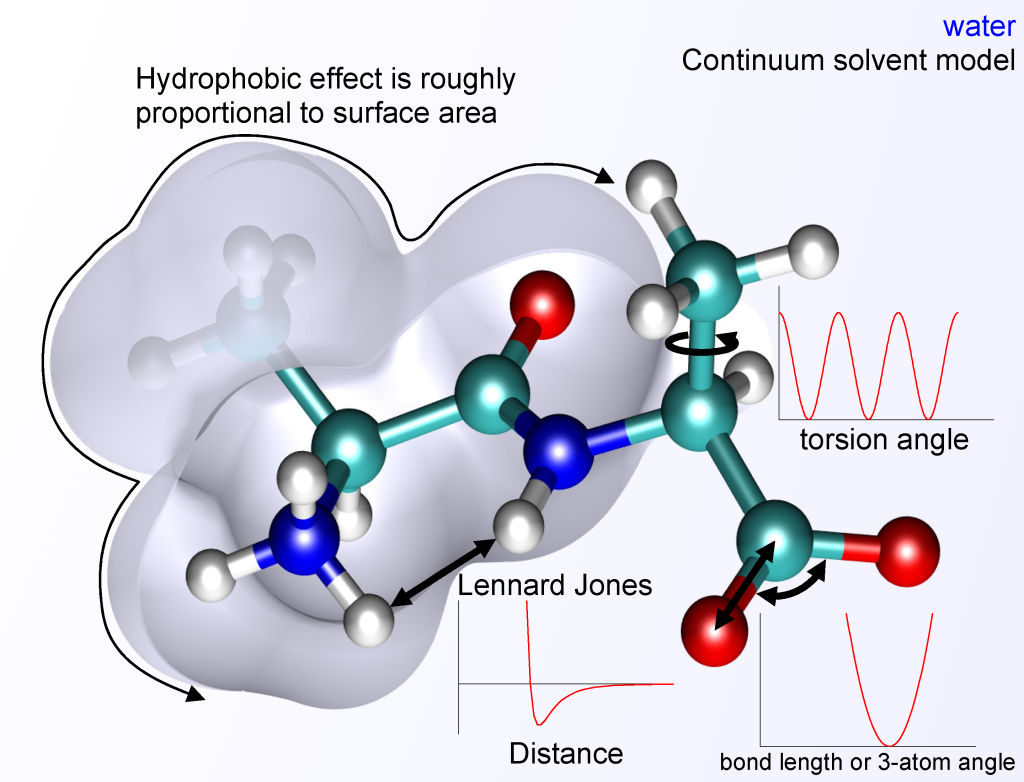

核心组成部分:功能形式与参数集
每个分子力场都由两个相互依赖的核心部分构成:功能形式和参数集。
E total = E stretch + E bend + E torsion + (E vdW + E electrostatics)
功能形式定义了用于根据原子坐标计算体系势能的数学方程。这些方程通常包括分子内(键合)相互作用项和分子间(非键合)相互作用项。
键合相互作用:描述通过共价键连接的原子之间的相互作用。常见的项包括:
键伸缩:通常采用谐振子(胡克定律)势能函数近似,假设能量与键长偏离平衡值的平方呈二次关系。这需要键力常数和平衡键长作为参数。
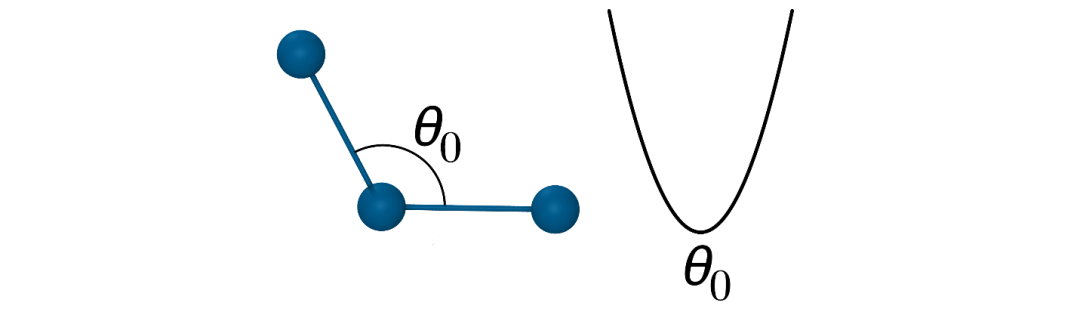
键角弯曲:类似于键伸缩,通常也用谐振子势能函数描述,围绕平衡键角进行弯曲,需要键角力常数和平衡键角。
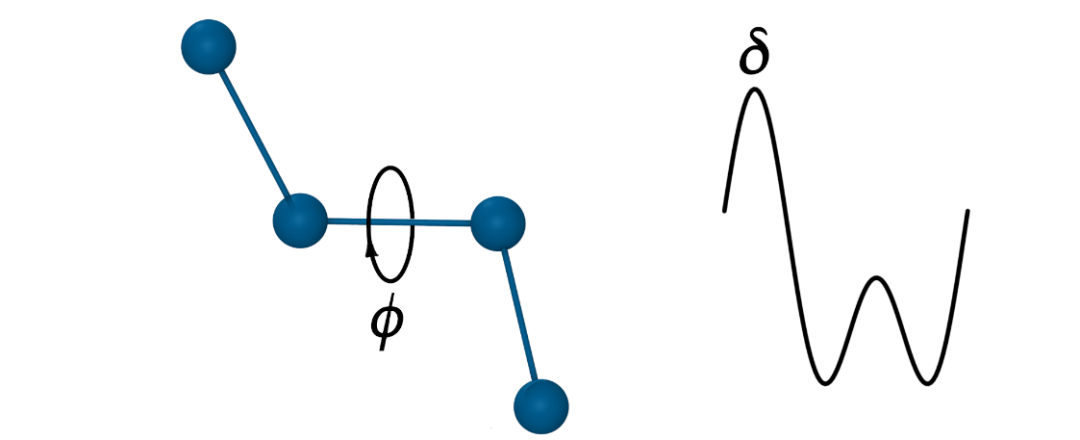
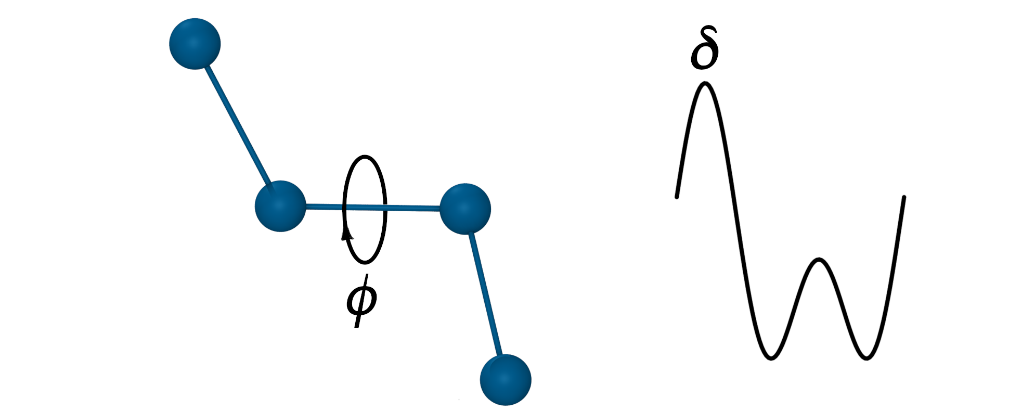
二面角(扭转)项:通过一系列余弦函数的和来表示,这些项对于准确再现构象能量至关重要,它们描述了绕中心键旋转时能量的变化。
非正常二面角(离面弯曲):通常用于维持特定分子中心的平面性或描述离面运动。
某些力场还可能包含Urey-Bradley 势能,用于描述键长和键角之间的耦合作用。
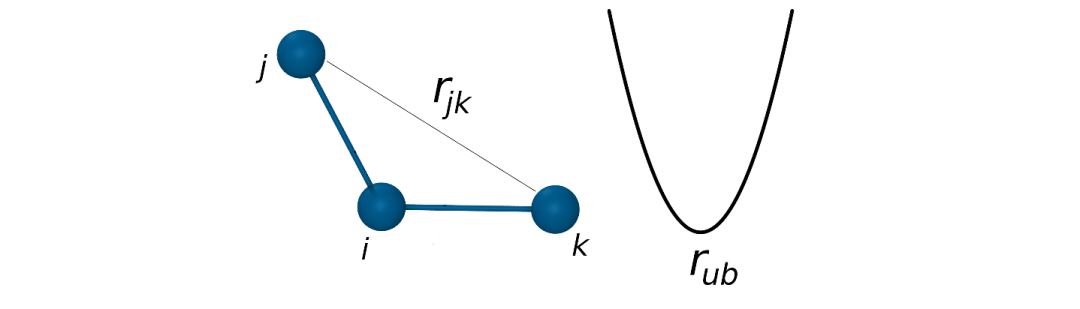
VUB=kub(rjk−rub)2
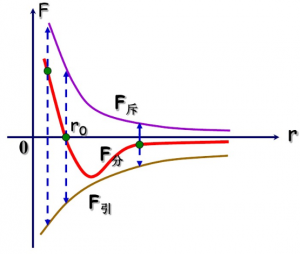
非键合相互作用:描述未通过共价键直接连接的原子之间的长程力。通常包括:
静电相互作用:使用库仑定律建模,其中原子电荷被分配以表示电荷分布。相互作用能与两个原子之间的距离成反比 (VElec=qiqj/(4πϵ0ϵrrij)) 。
范德华相互作用:通常由Lennard-Jones势能函数描述,它解释了短程排斥和长程吸引。这些相互作用通常是短程的,随距离迅速衰减(例如,r−6 依赖性) 。
对于通过三个键(1-4相互作用)分隔的原子,非键合相互作用通常会被缩减或排除,以防止在短距离内高估力 。
分子间作用力示意图
参数集包含了功能形式中常数的数值,例如力常数、平衡几何结构和部分电荷。这些参数通常通过结合实验数据(如X射线晶体学、核磁共振、红外光谱)和高水平量子力学计算来获得 。
用于参数化的数据质量和广度是决定力场准确性和可转移性的关键因素。原子类型不仅根据元素定义,还根据其特定的化学环境(例如,水中的氧原子与羰基中的氧原子)进行细致分类,以确保相互作用的准确表示。
力场的准确性和效用是其所选功能形式(平衡了精度和计算效率)与精细参数化过程(旨在将这些形式拟合到实验或高水平QM数据)之间协同作用的直接产物。功能形式的选择与数值参数的分配过程紧密相连。一个高度精确的功能形式可能在计算上难以承受,而一个过于简单的形式则可能缺乏必要的精度。
参数化过程则是在选定的功能形式内优化参数,以最佳地重现目标数据 。这表明力场的改进可以来自两个主要途径:开发更复杂的功能形式(如可极化、反应性力场)或改进参数化方法(如更好的数据、高级优化算法、防止过拟合的正则化方法)。
力场与分子模拟
力场是分子动力学(MD)模拟的核心,它使得研究分子随时间的动态行为成为可能,包括其柔性、稳定性以及与其他分子的相互作用 。力场在评估分子相互作用方面的计算速度对于模拟大体系和长时尺度至关重要,这对于理解复杂的生物现象是必不可少的。
尽管分子力学力场具有实用性,但其也存在固有的局限性。由于它们基于经验参数化和经典近似,其精度可能受限于量子力学方法。它们可能无法准确捕捉某些电子效应,例如电荷转移、极化或化学反应。
此外,没有一个力场能普遍适用于所有体系,其精度高度依赖于用于参数化的数据质量和广度。力场的功能形式本身是经验性的,代表了精度和计算效率之间的折衷。
力场的经验性质,即依赖于拟合参数,使得参数化成为一个关键且具有挑战性的步骤。这导致了其可转移性和普遍适用性方面的根本局限性,意味着不同的力场针对不同的分子类别或应用进行了优化。对特定训练数据进行参数化的依赖直接导致了其缺乏普遍适用性。
这反过来又使得开发众多专用力场成为必要,并使“力场选择”成为任何模拟项目中的关键步骤。这也解释了为什么“原子类型”如此具体(例如,水中的氧与羰基中的氧 ),因为它们是根据化学环境定义的,以提高特异性。
力场核心组成与相互作用项
传统力场
加和性力场的功能形式
传统力场主要具有“加和性”的特点,这意味着它们的静电参数是固定的,不会随着周围环境的变化而调整。因此,总静电能仅仅是各个原子间项的简单加和 。
在键合相互作用方面,传统力场通常采用简化的形式。例如,Class 1 力场使用简单的谐振子模型(二次近似)来描述键伸缩和键角弯曲的动力学,并省略了这些项之间的关联。相比之下,Class 2 力场通过在键和键角势能中添加非谐(三次和/或四次)项,并引入描述相邻键、键角和二面角之间耦合的交叉项,从而提高了精度 。
非键合相互作用则根据既定的经典物理原理进行计算。静电贡献通过库仑定律计算,使用固定的原子部分电荷,而范德华相互作用通常由Lennard-Jones势能函数描述 。
在许多力场中,对于通过三个键(1-4相互作用)分隔的原子,非键合相互作用通常会被缩减或排除,以防止在短距离内高估作用力 。
参数化方法与挑战
参数化——确定力场函数数值参数的过程——对于任何力场的准确性和可靠性都至关重要 。参数通常通过结合实验数据(例如,用于键常数的红外或拉曼光谱)和高水平量子力学计算来获得。
参数化过程中使用的特定目标数据直接影响力场的优缺点。迭代的参数化过程通常包括:1)使用当前力场计算目标数据;2)将这些结果与实际的实验或QM目标数据进行比较;3)调整力场参数以最小化差异 。
参数化面临的重大挑战包括:
数据需求:大量准确的参考数据(实验或QM)对于完整的参数化工作至关重要 。
优化复杂性:参数化本质上是一个高维优化问题,需要高效且稳健的方法来搜索庞大的参数空间。
过拟合:这是一个常见且严重的问题,当参数集中存在近乎或精确的冗余时,优化算法可能会产生物理上反直觉或无意义的参数值。为了防止这种情况,通常采用正则化方法,例如Tikhonov正则化,将参数限制在物理直观的范围内并防止过拟合 。
可转移性:尽管可转移性是力场的一个关键属性,但将从小分子数据中开发的参数应用于大分子体系时,需要仔细考虑原子类型,因为原子类型高度依赖于化学环境。
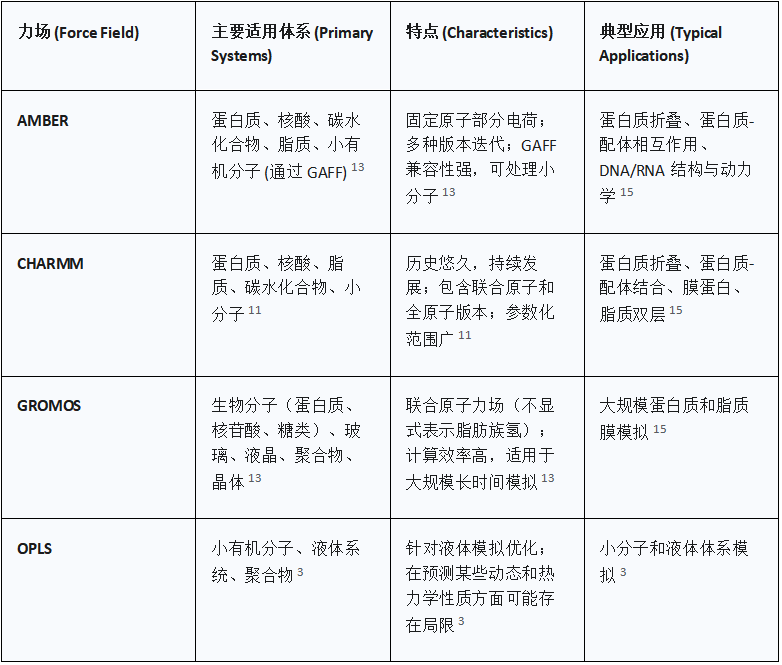
主要传统力场及其特点:AMBER, CHARMM, GROMOS, OPLS
传统(加和性)力场在根本上受限于其固定电荷近似。这意味着它们无法准确地解释电子极化现象,而这在不同的化学环境中以及特定相互作用中至关重要。这种固有的局限性直接导致了可极化力场的发展,旨在提高在电荷重新分布显著的体系(如水)中的精度。
尽管存在这些局限性,但“传统”力场并非一成不变,而是经历了持续的改进和版本迭代(例如,AMBER的多个版本,CHARMM的更新)。这种迭代的改进过程通常由与实验数据和量子力学计算的比较驱动,旨在提高其精度并将其适用范围扩展到更广泛的体系和现象。这意味着用户应始终了解其所使用的力场的具体版本,并查阅最新文献,因为新版本通常会解决已知的缺陷。
以下是几个主要的传统力场及其特点:
AMBER (Assisted Model Building and Energy Refinement):这个名称既指一套广泛使用的分子力学力场,也指一个用于生物分子模拟的综合软件包。AMBER力场主要为生物分子设计,具有针对蛋白质(例如ff19SB, AMBER99SB-ILDN)、DNA (OL21)、RNA (OL3)、碳水化合物 (GLYCAM_06j) 和脂质 (lipids21) 的特定参数化 。
它们传统上使用以原子为中心的固定部分电荷。通用Amber力场 (GAFF) 扩展了AMBER的适用性,使其能够应用于小有机分子,同时确保与蛋白质/核酸力场的兼容性 。AMBER广泛应用于蛋白质折叠、蛋白质-配体相互作用以及DNA/RNA结构和动力学研究 。
CHARMM (Chemistry at HARvard Macromolecular Mechanics):与AMBER类似,CHARMM既指一套力场,也指一个用于分子动力学模拟的强大软件包 。它被认为是生物分子研究中最成功的加和性力场之一,自20世纪70年代末问世以来,已取得了显著发展 。
CHARMM包括联合原子(例如CHARMM19)和全原子(例如CHARMM22, CHARMM27, CHARMM36)力场 。其参数化已扩展到涵盖脂质、碳水化合物、小分子药物,甚至石英等特殊材料。CHARMM力场在蛋白质折叠、蛋白质-配体结合、膜蛋白和脂质双层研究中表现出色 。
GROMOS (GROningen MOlecular Simulation): GROMOS是一个通用分子动力学模拟软件包,也拥有自己的力场。它适用于广泛的体系,包括生物分子(蛋白质、核苷酸、糖类)以及各种化学和物理体系,如玻璃、液晶、聚合物和晶体 。GROMOS力场通常是联合原子力场,这意味着它们不显式表示脂肪族氢原子 。
它们以在大规模生物分子动力学模拟中出色的计算效率而闻名,使其适用于更长的时间尺度和更大的体系。然而,值得注意的是,一些GROMOS力场是使用物理上不正确的多次时间步进方案进行参数化的,这在使用现代积分器时可能会影响密度等性质 。
OPLS (Optimized Potential for Liquid Simulations): OPLS是由William L. Jorgensen教授开发的一套力场,专门针对液体模拟进行了优化 。它们非常适合小有机分子和液体体系。
尽管经典的OPLS力场在捕捉聚合物体系的密度等性质方面取得了成功,但其准确预测某些动力学和热力学性质(如自扩散系数、粘度和比热)的能力通常仅限于获得相对趋势 。
常见传统力场对比
第二代力场
传统力场在处理电子极化和化学反应等复杂现象时存在固有限制,这推动了第二代力场的发展。第二代力场旨在通过更精细的物理模型来克服这些挑战,从而提高模拟的准确性和适用范围。
极化力场
极化力场通过允许原子电荷分布根据其环境动态调整来弥补传统力场的不足。在真实物理体系中,当分子处于高介电环境中(如水)或强带电体系接近中性物体时,会发生显著的极化,这强烈影响分子识别的几何结构和能量。传统力场中固定的原子电荷无法适应这种变化,而极化力场则能解决这一问题。
极化效应的建模主要有两种方法:
诱导点偶极模型 (Inducible Point Dipole Model):在这种方法中,每个原子中心都会根据总电场感应产生一个点偶极。总电场由永久原子电荷产生的场和(其他)诱导偶极产生的场组成。总场通过迭代过程自洽确定,以最小化极化能。
涨落电荷模型 (Fluctuating Charge Model):这种方法根据电负性均衡原理,允许原子电荷随环境波动。电荷在原子之间流动,直到原子的瞬时电负性相等。
极化力场在许多方面优于传统力场。例如,它们能够更准确地预测液态水的扩散常数,与实验结果更吻合。此外,极化力场在描述离子液体等带电体系时表现出显著优势,这些体系由于其带电性质,很难用传统力场准确模拟。
AMOEBA和Drude振子模型是两种著名的可极化力场 。AMOEBA(用于生物分子应用的原子多极优化能量)力场由Pengyu Ren和Jay W. Ponder开发,并逐渐向更具物理丰富性的AMOEBA+发展 。Drude振子模型则通过将无质量带电粒子通过谐波弹簧连接到原子上来模拟极化,CHARMM-Drude和OPLS5是其典型代表 。
反应力场
与传统力场不同,反应力场能够模拟化学反应中键的形成和断裂。传统力场的函数形式依赖于明确定义的键,因此无法处理键的动态变化。反应力场则通过引入“键序”概念来规避这一限制,允许键的连续形成和断裂 。
反应力场在描述键强度方面具有额外的项,这些项会根据环境动态调整键的强度。这使得分子键能够在模拟中断裂和重新形成,从而在不使用量子力学的情况下进行化学反应模拟。
例如,ReaxFF力场已被广泛用于研究碳氢化合物体系的热解和燃烧,它能够在较低的计算成本下模拟化学反应,并达到接近量子化学方法的精度,从而能够处理包含数千个原子的体系及其化学反应 。非反应力场适用于物理过程(无化学反应),而反应力场则适用于涉及新键生成和化学转化的过程。
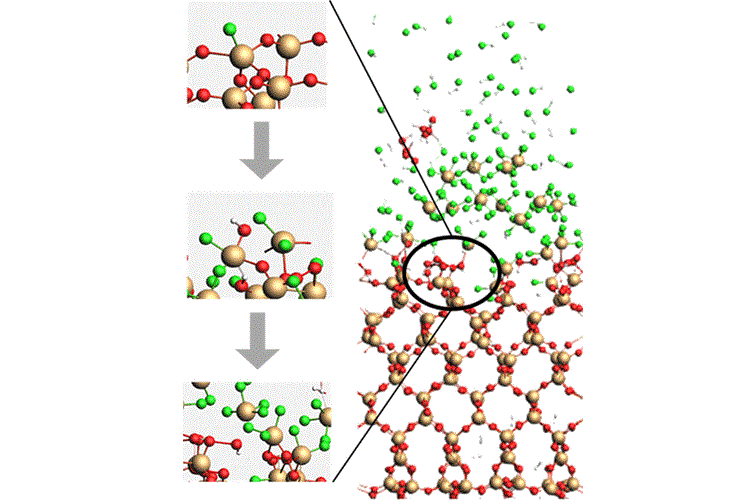
氟化氢刻蚀二氧化硅的ReaxFF分子动力学模拟
ACS Omega 2021, 6, 24, 16009–16015
混合量子力学/分子力学 (QM/MM) 方法
混合量子力学/分子力学(QM/MM)方法是一种强大的计算策略,它将量子力学(QM)计算的精度与分子力学(MM)力场的效率相结合 。这种方法特别适用于模拟溶液或酶中的化学反应,其中只有体系的反应部分需要高精度的量子力学处理,而其余部分则可以使用计算成本较低的分子力学力场进行建模。
在QM/MM方案中,QM区域的电子与MM原子之间以及QM原子核与MM原子之间的静电相互作用被明确地包含在QM子体系的哈密顿量中,这是一种“静电嵌入”方案的变体 。
为避免重复计算,QM原子上的经典MM电荷通常被置零,并且QM-QM原子之间的Lennard-Jones相互作用也被排除。然而,QM-MM原子之间的Lennard-Jones相互作用通常保留并由MM力场计算。QM和MM子体系之间的键合相互作用则由MM力场的相应项描述。QM区域内部的所有键合相互作用(如键、键角、二面角)通常从MM力场评估中排除。
当QM和MM子体系之间存在断裂的化学键时,需要在QM计算中对QM区域进行“封端”,通常通过添加氢原子来完成。这些封端原子上的力会分布到原始键的两个原子上 。QM/MM方法使得研究酶催化等大型体系中的化学反应成为可能,其中反应位点可以进行量子力学处理 。然而,QM部分的计算成本通常随原子数量的立方关系增长,因此QM区域应尽可能小而紧凑,以保持计算的可行性 。
力场选择
选择标准
选择合适的力场是分子模拟成功的关键,因为它直接决定了模拟结果的准确性、可靠性、计算成本和效率。一个优秀的力场应能重现体系的实验性质,如几何结构、能量、热力学、动力学和光谱等,并应在不同体系和条件下保持一致性和可转移性。
由于没有一个“万能”力场适用于所有体系和应用,因此在选择时需综合考虑以下因素 :
体系的性质:这是首要考虑因素。模拟蛋白质、核酸、小分子、膜或金属簇等不同类型的分子时,应使用专门为此类体系优化的力场。例如,AMBER或CHARMM力场适用于生物大分子,而OPLS或GROMOS可能更适合小有机分子或液体体系 。
精度与效率的平衡:需要根据研究目标确定所需的细节水平。全原子力场提供原子级别的精度,但计算成本高;而联合原子或粗粒化力场则通过牺牲部分细节来提高计算效率,适用于更大体系或更长时间尺度的模拟。简单的非极化力场(如MMFF或UFF)计算效率高,适合快速筛选或大体系模拟 。
模拟目标:模拟的目的是什么?是研究结合亲和力、构象变化、溶剂化动力学还是其他方面?每个力场都针对特定的实验数据进行验证,因此应确保其与研究目标一致。例如,如果涉及化学反应,则必须选择反应力场。
计算资源:更详细的力场需要更多的计算能力,可能会限制体系的大小或模拟的时长。对于需要大量模拟或长期动力学研究的情况,选择计算效率更高的力场可以提高研究的可行性。
社区与验证:查阅文献,了解哪些力场已成功应用于类似体系或应用。选择经过广泛验证且在文献中有良好支持的力场,可以增强模拟结果的可靠性。
性能测试:在进行最终模拟之前,应在自己的体系上测试所选力场的性能。通过执行能量最小化、几何优化或短期分子动力学运行等初步计算,评估力场是否能重现预期的结构、稳定性、动力学,并与实验数据或其他理论方法一致。
可访问性:考虑所选力场是否可用于所使用的软件工具,以及是否需要专有许可。
常见应用场景下的力场推荐
在分子动力学模拟中,生物大分子需要为复杂结构和相互作用设计的力场。不同的力场提供独特的优势,因此选择合适的力场对于获得准确的模拟结果至关重要。
生物大分子(蛋白质、核酸、脂质、碳水化合物):AMBER和CHARMM是最广泛使用的生物大分子力场,它们包含详细的参数和功能来描述氨基酸、核酸基团和脂质分子之间的相互作用。它们在蛋白质折叠、蛋白质-配体结合、膜蛋白和脂质双层研究中表现出色 。
GROMOS也是适用于生物分子的经典力场,尤其在处理大规模分子动力学模拟时。它适用于蛋白质、核酸和脂质体系,并擅长长时间和大尺度模拟,具有出色的计算效率。
小有机分子:OPLS力场或GAFF (Generalized Amber Force Field)通常是合适的选择。GAFF旨在为小分子提供与AMBER蛋白质/核酸力场兼容的参数 。
涉及化学反应的体系:必须选择反应力场,例如ReaxFF或AIREBO。这些力场能够模拟键的形成和断裂。
需要考虑电子极化的体系:应考虑使用可极化力场,如AMOEBA或Drude振子模型。这些力场能够动态调整部分电荷和极化,从而获得更准确的静电相互作用。
需要平衡精度和效率的大体系或长时尺度模拟:粗粒化 (Coarse-grained)或联合原子 (united-atom)力场可以提供精度和效率之间的良好平衡。
药物-蛋白质结合等高精度研究:可能需要更精细的力场,或结合不同力场(例如,在特定区域使用精确力场,在其他区域使用简化力场)以平衡精度和计算资源。
机器学习力场
基本原理与优势
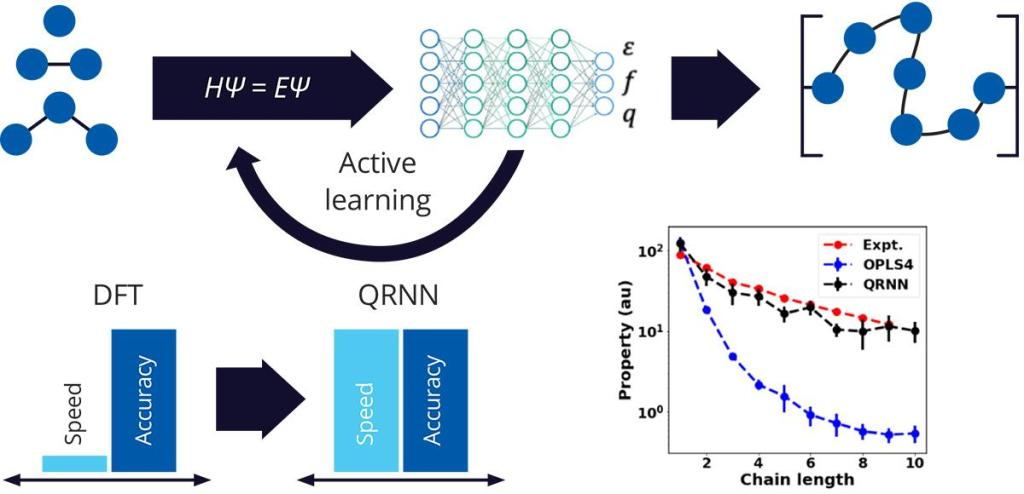
机器学习力场(MLFFs)代表了计算化学和材料科学领域的一项革命性进展,它们通过整合机器学习模型,旨在比传统力场更准确地模拟原子和分子间的相互作用 。MLFFs的核心优势在于它们能够结合量子力学方法的精度与分子力学力场的计算效率,从而实现比从头算方法快几个数量级的计算速度 。

深度学习力场训练流程图
MLFFs的关键优势包括:
高精度:它们能够有效地学习控制原子相互作用的潜在能量表面,甚至在传统经验参数力场难以处理的复杂无机和有机体系中也能表现出色。例如,MLFFs能够实现DFT(密度泛函理论)级别的精度,有效解决了传统力场在尺寸和时间尺度上的限制 。
动态电荷和极化调整:传统力场的一个局限性是无法调整变化的原子部分电荷和极化,导致静电相互作用不准确。MLFFs则能够动态调整部分电荷和极化,从而产生更准确的动力学模拟 。
处理复杂体系:它们能够对复杂体系(如聚合物、离子液体和电解质)的性质进行定量准确的预测,甚至超越传统力场的能力。离子液体由于其带电性质,传统力场难以准确模拟,而MLFFs可以更好地拟合 。
加速发现: MLFFs能够实现传统方法难以或不可能进行的动力学模拟,从而加速新分子和新材料的发现和优化 。
发展现状与挑战
尽管MLFFs展现出巨大潜力,但其发展仍面临一些挑战:
数据需求: MLFFs的训练通常需要大量的、高质量的第一性原理计算数据。对于复杂的实际体系,如表面、界面、重掺杂材料和非晶态材料,训练过程变得极其困难且成本高昂。
训练效率:传统的MLFF训练过程效率低下,即使对于简单的晶体,也往往需要数千次昂贵的第一性原理计算,并依赖于并发学习和迭代优化等高级技术 。
泛化能力:受限于原始模型架构和参数化,许多MLFFs的泛化能力较差,只能覆盖狭窄的化学范围 。
通用力场的挑战:旨在跨越元素周期表实现通用化的力场代表了计算材料科学的新趋势。这些通用力场在经过数百万次第一性原理计算的训练后,展现出卓越的泛化能力。然而,它们仍面临关键挑战:
精度不足:通用力场的能量误差通常在每原子几十meV的范围内,这对于需要第一性原理精度(能量误差在每原子几meV以内)的材料模拟可能不足 。
计算成本高:由于模型架构复杂,通用力场的计算成本通常更高。这使得它们不适合需要数万个原子的精确大规模材料模拟。
为了解决这些挑战,研究人员正在开发新的工作流程模式,例如PFD(Pre-trained model Fine-tuning and Distillation)。PFD通过对预训练的通用模型进行微调和蒸馏,自动生成特定材料的MLFFs。
与传统训练方法相比,PFD工作流程所需的第一性原理计算量减少了1到2个数量级,显著节省了时间和计算资源。这种方法还使得构建复杂材料(如非晶相和材料界面)的实用力场成为可能 。
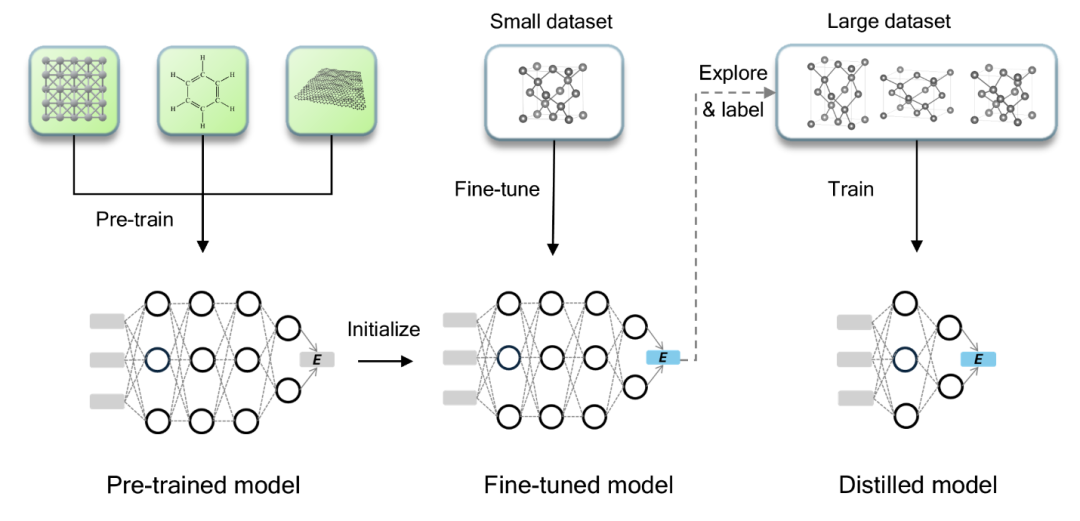
https://doi.org/10.48550/arXiv.2502.20809
典型模型
机器学习力场涵盖多种模型,其中神经网络势能和基于核函数的方法是主流:
神经网络势能:这类模型使用神经网络来学习原子相互作用的复杂关系。典型的例子包括SchNet和DeePMD。SchNet模型通过原子类型嵌入和相互作用块来描述原子环境和能量 。DeePMD等模型在保持DFT级别精度的同时,有效扩展了模拟的尺寸和时间尺度 。
基于核函数的方法:这类模型利用核函数来构建势能表面。典型的例子包括GAP (Gaussian Approximation Potentials)和GDML (Gaussian Process Regression for Molecular Energies)。GDML框架展示了核函数优雅的公式如何用于构建数学上稳健且受物理启发的MLFFs 。
应用案例
分子力场在多个科学和工程领域中发挥着基础性作用,尤其是在需要原子级别模拟和预测的场景。
药物发现与设计
分子力学(MM)力场在计算结构辅助药物发现(CSBDD)项目中至关重要,它们是研究蛋白质构象柔性的首选方法 。力场在药物设计程序中被广泛用作“描述符”和“评分函数”,用于排名对接算法获得的“配体姿态”,或在新配体设计程序中建议片段在酶中具有最高结合亲和力的位置 。
对接与评分:力场用于计算蛋白质与配体之间的相互作用能,包括范德华力、静电相互作用以及配体与酶之间的氢键能。AMBER、GOLD、AutoDock和DOCK等药物设计软件都已将力场作为评分函数实现 。
自由能微扰(FEP)计算:力场在自由能微扰计算中也发挥着重要作用,这使得能够准确预测新类似物或抑制剂的活性。
计算辅助药物设计(CADD)和机器学习(ML): CADD方法和ML在过去二十年中变得更加有效,能够快速、灵活且足够准确地加速新分子和材料的发现和优化 。这些方法在预测药物的药代动力学特性、与关键酶的相互作用以及在生物环境中的稳定性方面发挥关键作用,从而简化药物设计并降低实验成本。
材料科学
力场在材料科学中用于理解和预测各种材料的性质和行为,特别是分子晶体、聚合物和离子液体等。
分子晶体:分子晶体由通过非键合相互作用结合的单个分子组成,如范德华力、偶极-偶极相互作用、π-π相互作用和氢键 。力场用于预测晶体的晶格能和密度等重要性质。
例如,COMPASS(凝聚相优化分子原子模拟势)力场及其扩展版本COMPASSIII被广泛用于预测分子晶体的凝聚相性质,并显示出优于其他力场(如DREIDING、Universal、CVFF、PCFF)的性能。COMPASSIII在预测235个晶体的晶格能方面R²达到0.70,在821个分子晶体的密度预测方面R²达到0.97 。
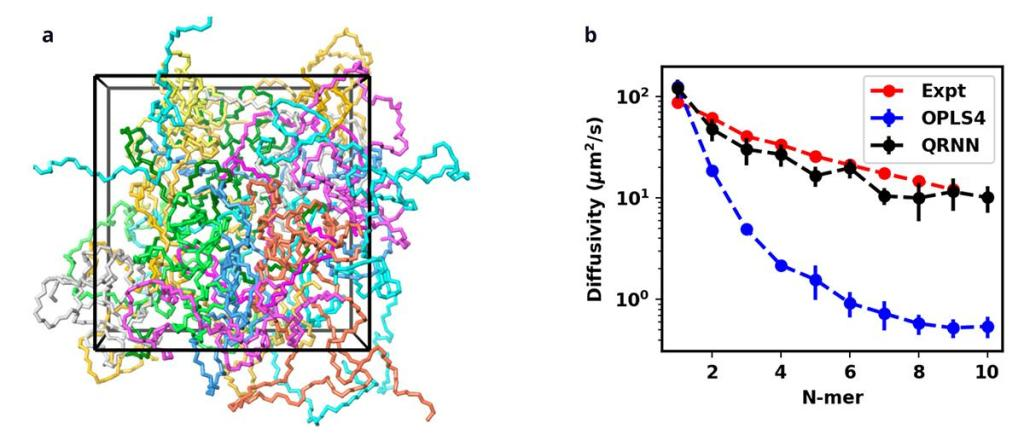
聚合物和离子液体:机器学习力场在模拟聚合物体系的动态和热力学性质(如自扩散系数、粘度和比热)方面超越了传统力场。对于离子液体,由于其带电性质,传统力场难以准确模拟,而MLFFs可以更好地拟合 。
其他应用:力场还用于研究晶体体系中的原子相互作用,例如,对于共价键晶体,通常使用键序势能(如Tersoff势),而对于金属体系,则常使用嵌入原子势能 。
生物分子模拟
分子力场在生物分子模拟中扮演着核心角色,用于揭示生物大分子的复杂行为和相互作用。
蛋白质折叠与构象柔性:力场是研究蛋白质构象柔性的首选方法,这对于药物结合至关重要。它们用于模拟蛋白质的动态行为,提供对其柔性、稳定性和与其他分子相互作用的见解。
蛋白质-配体相互作用:在药物发现中,力场用于模拟蛋白质与小分子药物之间的相互作用,例如AMBER力场广泛应用于此 。
DNA/RNA结构与动力学:力场用于研究DNA和RNA的结构和动态特性,例如AMBER力场在DNA/RNA结构和动力学研究中得到广泛应用 。
膜蛋白和脂质双层: CHARMM力场在膜蛋白和脂质双层研究中表现出色,其参数化适应各种分子的结构特征 。
无序蛋白:传统的力场在描述无序蛋白方面存在挑战,例如模拟出的无序态通常比实验估计的更紧凑。然而,通过优化参数和引入水模型中分散相互作用的微小变化,已经开发出能够同时准确描述折叠蛋白和无序蛋白的力场,例如a99SB-disp,这极大地扩展了分子动力学模拟在生物体系中的应用范围 。
未来展望
力场发展的趋势
分子力场的发展是一个持续动态的过程,并受到不断增长的实验数据和计算研究的深刻影响。未来的力场发展将呈现以下几个主要趋势:
持续的精度提升与功能扩展:现代力场高度参数化,整合了广泛的相互作用,包括超越简单库仑电荷-电荷项的静电相互作用,以及对更复杂、非加和现象(如空间极化)的显式考虑 。力场将继续向更高精度和更广泛适用性发展,以捕捉更细微的物理化学效应。
人工智能与机器学习的深度融合:机器学习力场(MLFFs)是当前最前沿的领域,它们通过机器学习策略来优化力场参数,使其更好地拟合实验数据或高水平量子力学计算结果 。
人工神经网络(ANN)势能等ML驱动的力场已经成为强大的工具,能够以传统力场难以达到的细节水平捕捉复杂相互作用 。未来,AI和ML将更广泛地应用于数据分析和预测,进一步推动力场的发展 。
混合方法与专业化力场:混合量子力学/分子力学(QM/MM)方法将继续发展,以在大型体系中进行化学反应的理论研究 。同时,针对特定体系(如膜环境或碳水化合物)定制的力场将允许进行更准确、更聚焦、更真实的模拟。
通用力场的突破:尽管当前通用力场在精度和计算成本方面仍面临挑战,但通过微调和蒸馏等先进的工作流程,有望实现既通用又精确高效的力场。这将极大地降低复杂材料模拟的门槛。
计算化学的未来挑战与机遇
计算化学领域尽管取得了显著进展,但仍面临多重挑战,同时伴随着巨大的发展机遇。
分子体系复杂性与精度:模拟复杂分子体系(如生物大分子、材料界面)仍然是一个挑战,需要更精确的近似方法。力场需要不断改进以准确描述这些复杂体系中的所有相关相互作用,特别是长程非共价相互作用,这对于所有MLFF模型来说仍然具有挑战性 。
数据解释与验证:模拟产生的大量信息使得数据的解释和验证变得复杂。未来的发展需要更先进的数据分析工具和方法来从海量模拟数据中提取有意义的化学和物理见解。
计算资源与技术进步:尽管计算机性能持续提升,但更精确、更大规模的模拟仍需要巨大的计算资源。高性能计算的进步将使科学家能够解决以前无法解决的问题,从理解复杂的生物分子相互作用到设计具有特定性质的新材料。
量子计算的潜力:量子计算有望为计算化学领域带来突破性进展,可能彻底改变我们模拟化学行为的方式。随着量子计算技术的发展,未来可能实现当前经典计算无法企及的精度和计算规模。
方法论的融合与创新:计算化学的未来将是算法、机器学习和人工智能深度融合的时代。这种融合将使化学空间快速筛选成为可能,而这在实验上是不可行的。
总结
分子力场作为计算化学的基石,通过提供原子间相互作用的经验模型,极大地推动了我们对分子体系结构、动力学和功能的理解。从最初的加和性力场到能够处理极化和化学反应的第二代力场,再到结合了量子力学精度和分子力学效率的机器学习力场,这一领域经历了显著的演变。
传统力场如AMBER、CHARMM、GROMOS和OPLS,通过其经验参数化和计算效率,在生物分子模拟和材料科学中发挥了不可或缺的作用。然而,它们在处理动态电子效应和化学反应方面的局限性,催生了可极化力场和反应力场的发展,以及QM/MM等混合方法的出现,这些方法旨在弥补精度上的不足。
机器学习力场代表了当前最前沿的进展,它们有望通过从第一性原理数据中学习,实现量子力学级别的精度,同时保持分子力学的高效率。尽管在数据需求、训练效率和泛化能力方面仍面临挑战,但微调和蒸馏等创新方法正在逐步克服这些障碍,预示着通用、准确且高效力场的未来。
力场的选择是模拟成功的关键,需要根据体系性质、模拟目标、计算资源和所需精度等因素进行权衡。未来,随着计算技术、算法和人工智能的不断进步,力场将继续演进,变得更加精确、通用和易用,从而使计算化学能够解决更复杂的问题,加速新分子和新材料的发现,并在药物设计、材料科学和生物分子研究等领域发挥日益重要的作用。