

机器学习(ML)作为人工智能的核心分支,其本质是构建能够从数据中自主学习的算法系统,而非依赖显式编程指令。根据Padamwar等人的精确定义,机器学习是“开发允许计算机基于数据进行预测或决策的算法与模型的领域,其核心在于通过经验实现自我改进”。
这种学习过程依赖于数学框架的支撑,包括统计学、线性代数和概率论等工具,这些数学基础使机器能够解析自然语言、识别视觉模式及执行物理任务。在技术实现层面,机器学习系统处理的基本单元包括数据点(如材料的化学成分或结构参数)、特征(如晶格常数或电子能带结构)和标签(如材料的热稳定性或导电性),通过构建输入特征与输出标签之间的映射关系形成预测模型。
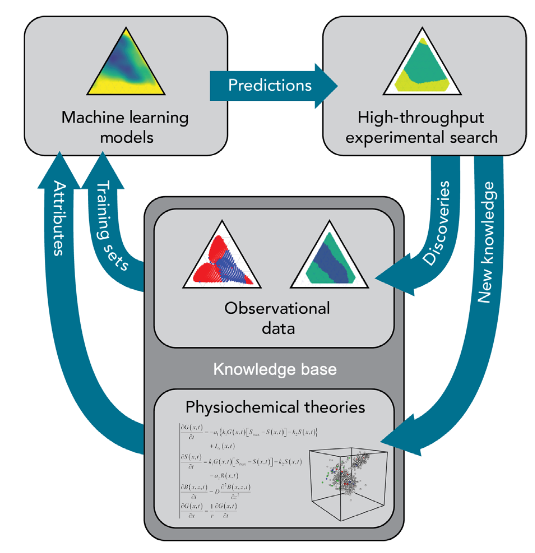
这种数据驱动范式正彻底改变材料科学的研发路径,将传统的“试错法”转变为“预测–验证”的高效循环。
机器学习在材料科学中的应用
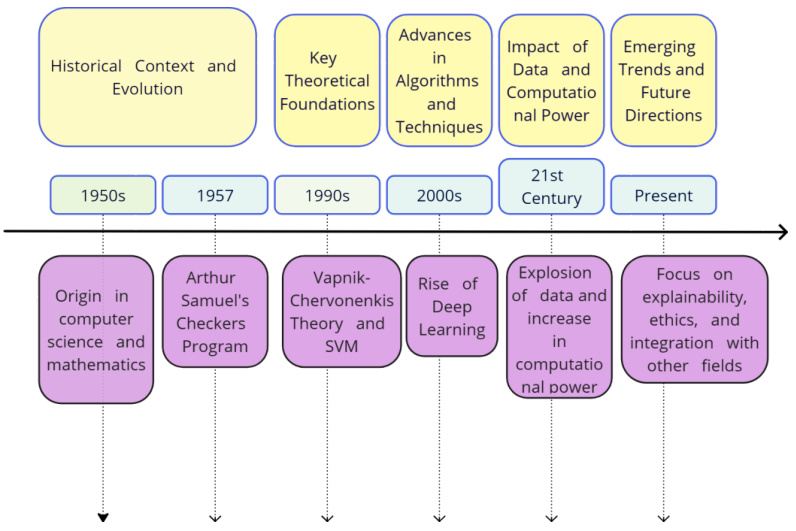
材料科学中机器学习应用的核心价值在于其能够建立复杂的“结构–性能”关系模型,从而加速新材料的发现与优化。如下图所示的技术演进历程,机器学习在材料领域的发展经历了显著阶段:1950年代的理论萌芽期(如Arthur Samuel的首个学习程序)、1990年代的算法突破期(支持向量机与VC理论的建立)、2000年代的数据驱动期(伴随高通量计算兴起),直至当前的多模态融合期(整合实验、模拟与理论)。
该时间轴底部标注的关键事件清晰展示了技术拐点,例如2006年深度学习在ImageNet竞赛中的突破性表现——通过五层卷积网络将图像分类错误率降至17%,这为材料显微图像分析奠定基础。特别值得注意的是,图中“新兴趋势”区域强调的可解释性AI与伦理框架,正推动材料机器学习从黑箱模型向透明化、可验证范式转型。

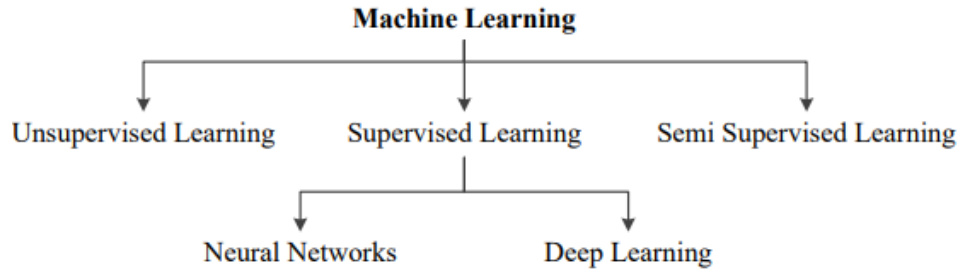
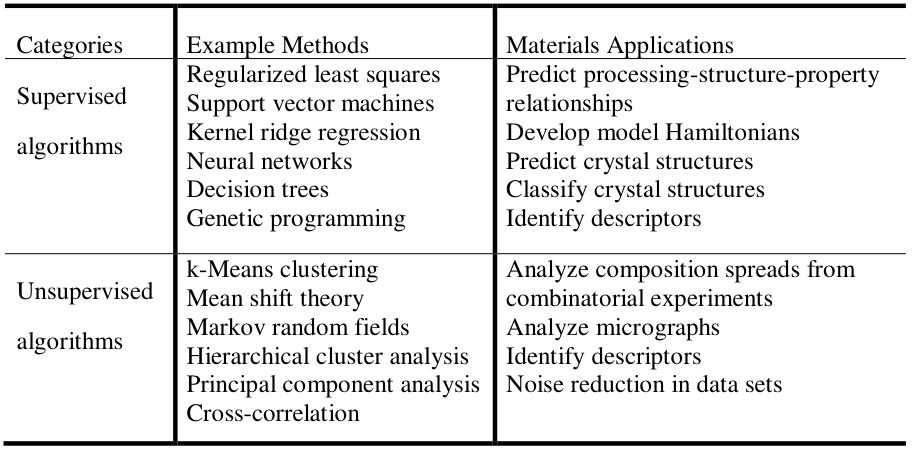
在技术分类层面,机器学习在材料领域的应用呈现三维架构:
DOI: 10.55627/pharma.002.01.0297
DOI: 10.1039/d0na00388c
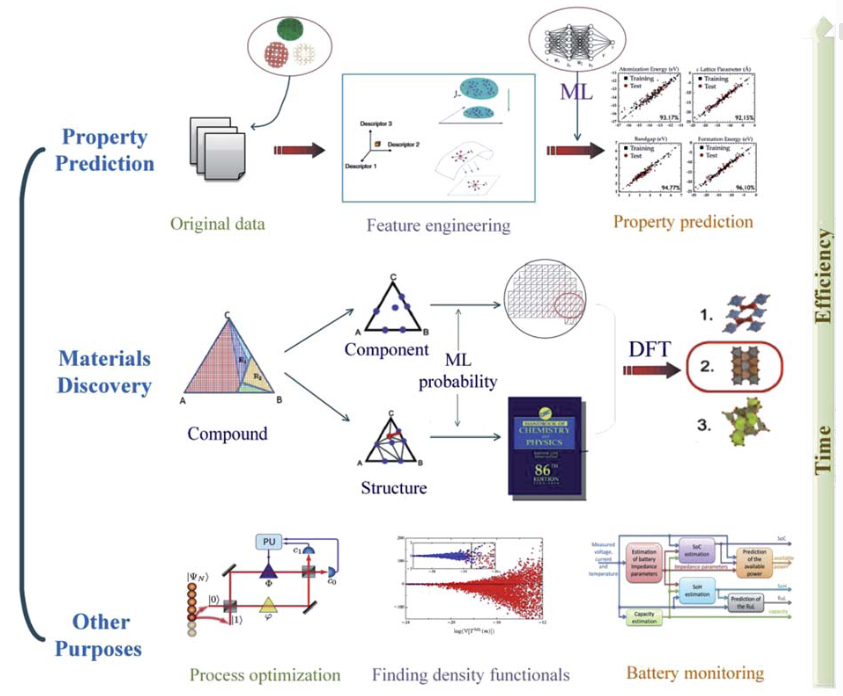
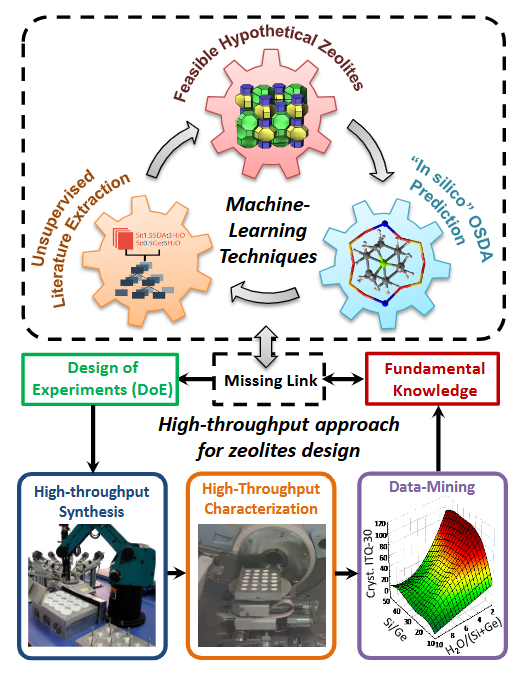
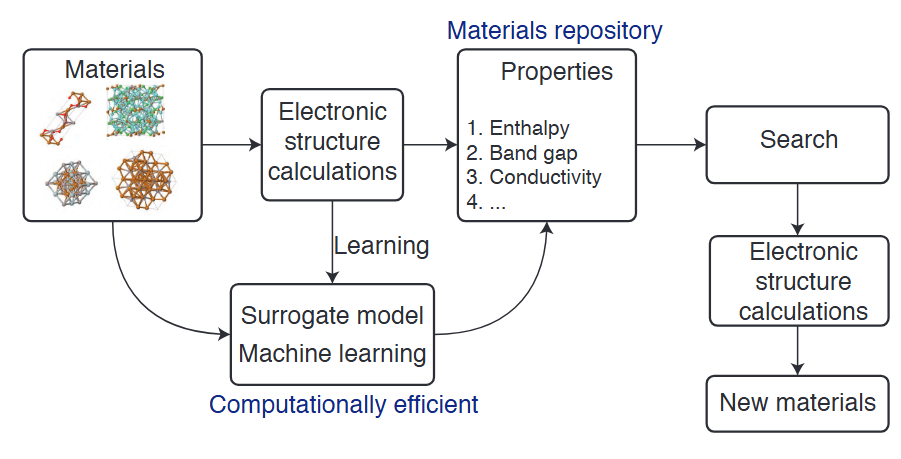
材料发现维度:通过无监督学习(如k均值聚类)分析海量化合物数据库,识别潜在的新型材料构型。例如在沸石合成中,研究者利用文本挖掘技术从25万篇文献提取合成参数,再通过高斯过程回归预测最优反应条件,将新型沸石开发周期缩短60%。
图中展示的高通量发现流程包含“文献提取→机器学习预测→OSDA验证→实验设计”的闭环,其中橙色箭头标明了数据反馈路径,显著提升预测准确性。
DOI: 10.1021/acs.accounts.9b00399
性能预测维度:监督学习算法(如晶体图卷积网络CGCNN)直接建立原子连接与宏观性能的关联。CGCNN框架将晶体结构转化为拓扑图(节点为原子,边为化学键),通过多层图卷积捕获局部化学环境特征。
该方法在预测钙钛矿形成能时达到0.08 eV/atom的误差,较传统DFT计算效率提升三个数量级,图中彩色映射清晰展示不同原子簇对整体能量的贡献度,实现模型的可解释性。
工艺优化维度:强化学习与主动学习结合指导实验设计。在金属玻璃研发中,研究者构建了“ML预测→高通量实验→数据反馈”的动态闭环:初始模型基于1,200组合金数据训练,通过贝叶斯优化推荐新成分配方;自动喷印系统每周合成200种合金,XRD表征数据实时回传更新模型。
图中迭代曲线显示,9周内金属玻璃形成能力预测精度从71%提升至95%,绿色箭头标明了数据流动对模型优化的正向增强效应。
DOI: 10.1126/sciadv.aaq1566
材料性能预测的算法与验证
材料性能预测是机器学习最具实用价值的应用场景,其技术核心在于选择适配材料特性的算法架构。如下表的系统分类,监督学习算法主要解决连续变量预测(如弹性模量)和离散分类问题(如相结构识别)。
回归模型中,核岭回归(KRR)通过高斯核函数映射非线性关系,在预测锂离子电池阴极材料容量时表现出色(R²=0.94)。其关键优势在于正则化项有效抑制过拟合,图中学习曲线显示当训练样本超过800组时,测试集误差稳定在±0.5%以内。
分类模型中,随机森林利用多决策树集成策略,在识别形状记忆合金相变点时达到92%准确率。算法通过Gini系数评估特征重要性(图中柱状图显示晶格畸变度占比达67%),为材料设计提供明确指导。
深度学习方法则突破传统特征工程的局限。晶体图卷积网络(CGCNN)的创新在于直接处理原子连接关系:输入层将晶体结构转化为图数据结构(节点为元素类型,边为键长键角);卷积层使用半径3Å的局部环境过滤器提取原子簇特征;全连接层整合全局信息输出性能预测。
该框架在Materials Project数据库验证中,对8,000种化合物的带隙预测误差仅0.15 eV,较手工特征模型精度提升40%。图中热力图清晰展示MoS₂边缘硫原子对导电性的显著贡献(红色区域),揭示二维材料性能优化的关键位点。
实验验证环节采用多尺度交叉校验策略:
DOI:10.1002/advs.202305277
DOI:10.1038/s41524-019-0189-9
计算验证层:代理模型预测结果需通过DFT计算验证,防止假阳性。在热电材料筛选中,机器学习初筛的ZrCoSb基化合物经DFT确认ZT值达1.2,与预测偏差。图中红色警示图标强调该步骤对可靠性保障的必要性。
实验验证层:高通量合成平台实现快速物性检测。例如在光伏材料开发中,溶液自动喷涂系统每日可制备1,500组有机薄膜,结合光谱椭偏仪实时测量光电转换效率。图中流程的蓝色箭头标明了“预测–合成–检测”循环可在72小时内完成。
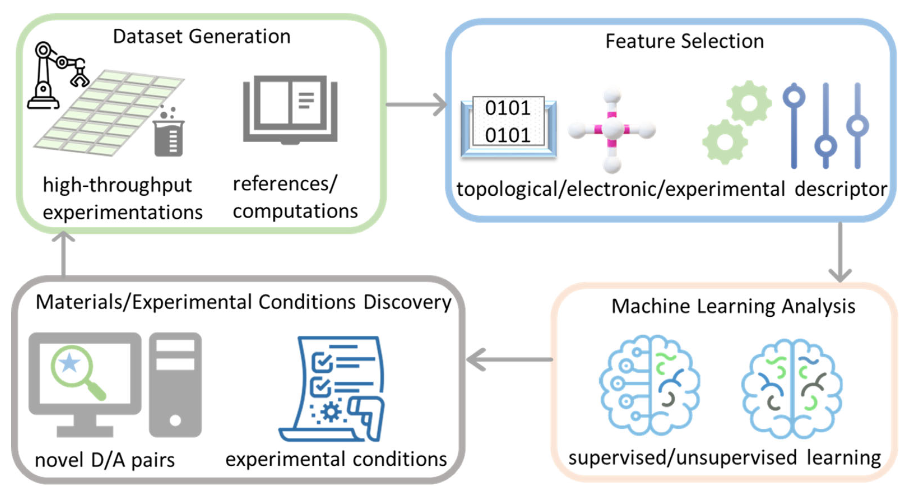
DOI:10.1002/aisy.202100261
机理阐释层:机器学习与理论模拟结合揭示微观机制。当预测发现新型铁电体BiFeO₃的居里温度异常升高时,分子动力学模拟显示机器学习未考虑的氧八面体旋转模式是关键诱因。这种多尺度校验框架将预测误差控制在可接受范围(通常),推动机器学习从辅助工具向决策支持系统演进。
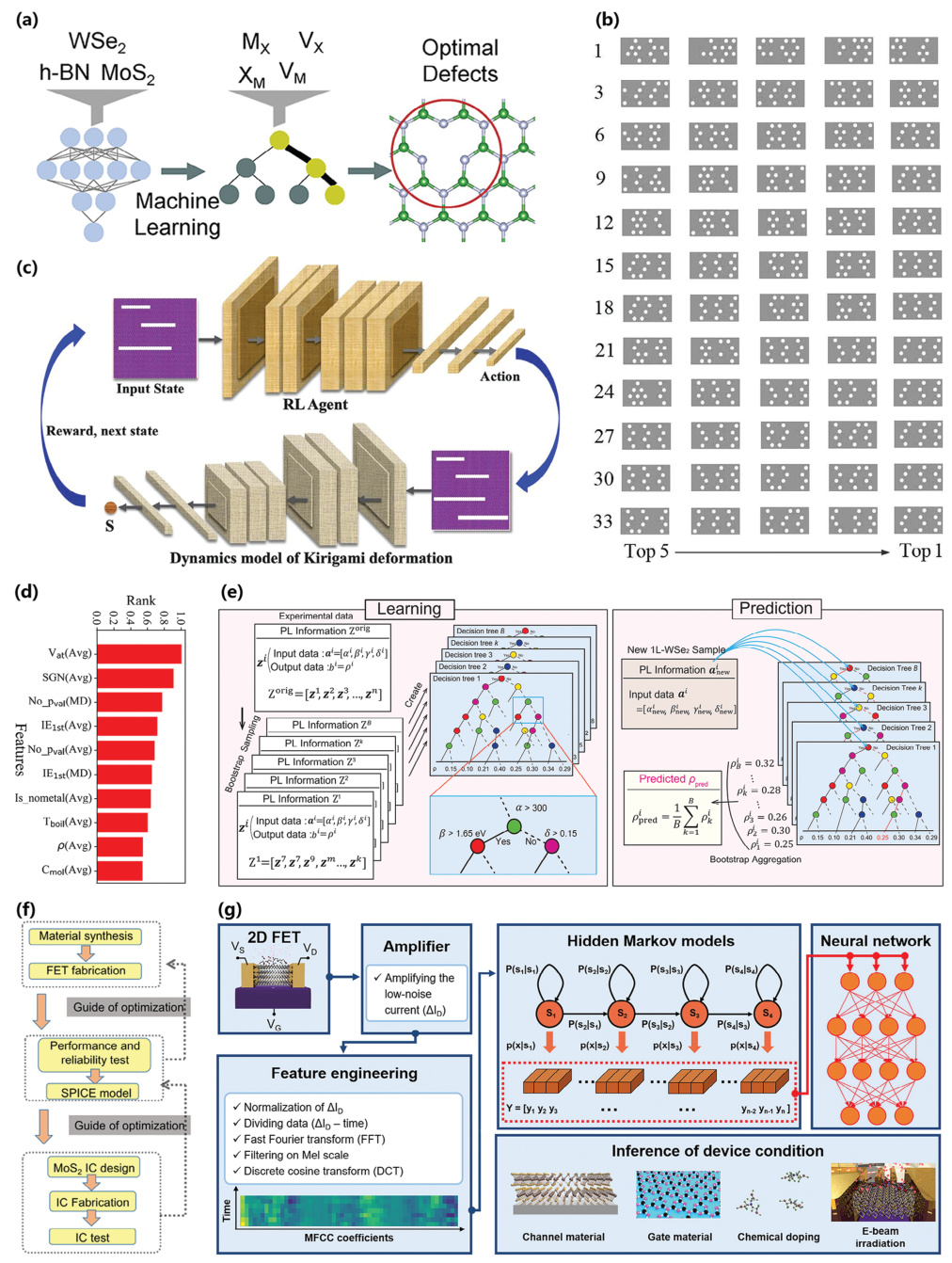
材料缺陷检测的深度学习应用
材料微观缺陷的智能识别是保障产品质量的核心环节,而深度学习凭借其强大的图像解析能力在此领域大放异彩。卷积神经网络(CNN)作为主流架构,在扫描电镜图像分析中展现显著优势:VGGNet通过16层卷积堆叠,利用3×3小卷积核捕获微裂纹的局部特征。
ResNet引入残差连接(图中跳跃箭头)解决深层网络梯度消失问题,使152层网络能识别纳米级孔洞。这些网络在金属增材制造缺陷检测中达到98.7%的召回率,较传统图像处理算法提升35%。
针对材料缺陷的动态特性,YOLO(You Only Look Once)框架实现实时检测革新:
单阶段检测机制:将缺陷识别转化为边界框回归问题,单次前向传播同时输出位置与类别。在陶瓷表面质检中,Fast YOLO版本以155帧/秒处理1024×1024图像,识别200nm级裂纹仅需8ms。图中红色检测框与置信度数值直观显示算法效能。
多尺度特征融合:结合浅层高分辨率特征与深层语义特征,精准定位不同尺寸缺陷。铝合金疲劳裂纹检测案例显示,该技术对微米级裂纹的定位误差像素,显著优于两阶段模型。
工业部署层面,端到端缺陷分析系统已实现落地应用:
数据采集模块:自动扫描电镜以1nm分辨率采集材料截面图像,通过数据增强生成10万+训练样本。
智能分析模块:集成ResNet-152特征提取器与FPN特征金字塔,构建缺陷分级模型(图中用不同颜色标注裂纹危险等级)。
决策反馈模块:预测结果实时传输至工艺控制系统,动态调整烧结温度等参数。在半导体晶圆生产中,该系统使缺陷率从1.2%降至0.3%,每年减少千万美元损失。图中控制台的实时数据流界面展示了异常工艺参数的自动标记功能(如氧含量超标警示)。
总结
尽管机器学习在材料科学中成果显著,其仍面临三重技术瓶颈:
数据瓶颈:高质量材料数据集稀缺且分布不均。研究表明,93%的公开数据集中于10%的常见材料体系(如氧化物陶瓷),导致模型对稀贵金属等体系预测误差激增200%。
解决方案包括开发主动学习算法:通过PTR获取函数评估数据价值,优先选择预期提升最大的样本进行实验。图中曲线显示,该方法仅用30%的数据量即达到全数据集95%的精度。
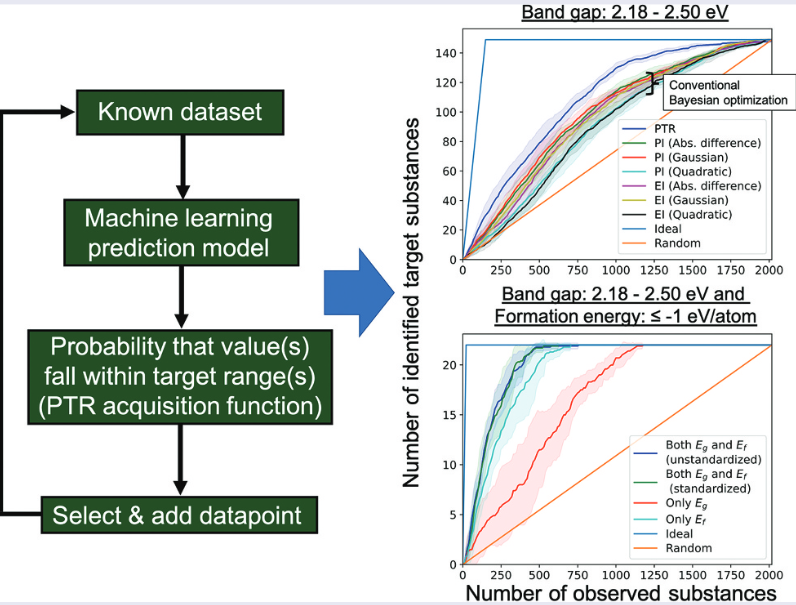
DOI:10.1080/27660400.2022.2039573
可解释性缺失:黑箱模型难以为材料设计提供机理指导。当预测发现超越Slater-Pauling极限的磁性合金时,模型无法解释其反常磁矩来源。新兴的符号回归技术(如Eureqa)正尝试将神经网络转化为显式数学表达式,图中公式显示某合金强度预测模型最终简化为晶格常数与电子浓度的二次函数。
跨尺度建模障碍:现有模型难以统一原子尺度与宏观性能。解决方案在于开发多尺度架构:图神经网络处理原子层面相互作用,CNN分析显微组织,全连接网络预测宏观性能。图中三色箭头标明不同尺度特征的自底向上传递路径,在复合材料强度预测中误差降至7%。
未来突破将依赖深度交叉融合:
机器人科学家平台:集成自主合成机器人(如液态金属喷射系统)、原位表征设备(如微区XRD)与强化学习算法,实现闭环研发。某实验室已实现每周自主完成200次合金合成–测试循环。
量子机器学习融合:量子计算加速材料模拟,生成训练数据。变分量子电路处理128维特征向量的速度已达经典计算机36倍。
联邦学习架构:跨机构安全共享数据而不泄露原始信息。Materials Genome Initiative已连接12国实验室,共享450万材料数据条目。
正如材料科学史上的每一次范式变革,机器学习并非替代人类智慧,而是将研究者从繁琐试错中解放,使其聚焦于创造性突破。当算法精确预测出下一个高温超导体或量子材料时,真正的科学革命才刚刚开始——那将是由人类智慧与机器算力共同谱写的材料新篇章。