

吸附能是量化吸附物与基底结合强度的核心物理量,定义为复合体系与孤立组分的能量差。其计算以DFT为主,需选择合适泛函并考虑范德华力修正,高阶方法如RPA可提升精度。吸附能广泛应用于催化设计、材料稳定性评估及高通量筛选,作为 “能量标尺” 连接微观结构与宏观性能,推动材料研究从经验探索向理性设计转变。
什么是吸附能
吸附能是理论计算中量化吸附物与基底结合强度的核心物理量,其定义为吸附体系总能量与孤立组分能量之差,数学表达式为 Eₐ=E(slab+B)-E(slab)-E(B),其中 E(slab+B) 代表吸附物与基底形成的复合体系的基态总能量,E(slab) 为未吸附时基底的基态能量,E(B) 则是游离态吸附物的基态能量。
计算吸附能时需遵循关键原则,即所有能量项必须在相同计算精度下获得,包括泛函选择、基组类型、K点网格密度等参数的一致性,以确保能量差的可比性。例如,若基底能量采用PBE泛函计算,吸附物与复合体系的能量也必须使用相同泛函,否则会因方法误差导致吸附能计算失真。
这一原则是保证吸附能在不同体系间横向对比、以及与实验结果关联的基础,使其能够有效反映吸附物与基底相互作用的本质,成为表面科学、催化化学等领域研究的基础物理量。

DOI:10.7498/aps.71.20220631
怎么计算吸附能
吸附能的计算方法多样,其中密度泛函理论(DFT)是当前主流手段,其通过求解Kohn-Sham方程获得体系总能量,适用于处理周期性表面模型,计算效率较高,能在原子尺度描述吸附物与基底的电子相互作用。
DFT的核心挑战在于交换关联泛函(XC)的选择,不同泛函对吸附能的计算精度影响显著:局域泛函(LDA)因过度考虑电子局域性,往往高估吸附能,例如在 CO/Cu (111) 体系中,LDA计算的吸附能比实际值高约0.5eV。
梯度修正泛函(如 GGA-PBE)虽改善了局域近似的缺陷,但普遍低估吸附能,尤其对涉及范德华力的弱相互作用描述不足,需额外修正;杂化泛函通过引入非局域交换能提升精度,但计算成本显著增加,仅适用于小体系或高精度验证。
对于弱相互作用(如π-π 堆积、氢键、分子物理吸附),需采用专门的范德华力(vdW)修正方法:DFT-D系列通过添加原子对色散项,基于第一性原理计算色散系数,适用于94种元素,能有效修正石墨烯层间作用或苯在Ag (111) 表面的吸附能;vdW-DF采用非局域泛函,对长程色散作用的描述更精准,适合处理石墨烯与金属的界面吸附;TS-vdW则针对大分子,可避免物理吸附与化学吸附的误判。
高阶计算方法虽精度更高,但成本昂贵:随机相近似(RPA)超越DFT框架,能显著提升弱相互作用描述精度,例如在CO/Cu (111) 体系中,RPA计算的吸附能为-0.6eV,接近实验值而 PBE泛函仅为-0.2eV;量子蒙特卡洛(QMC)作为高精度基准方法,计算结果可靠,但计算量极大,通常用于验证其他方法的准确性。
以CO吸附在Cu (111) 为例,不同方法的结果差异明显:LDA因过估键合作用得-1.8eV,PBE因忽略vdW得-0.2eV,PBE0部分修正得-0.5eV,而RPA结果最接近真实值,这些差异表明,根据体系特点选择合适的计算方法是保证吸附能精度的关键。
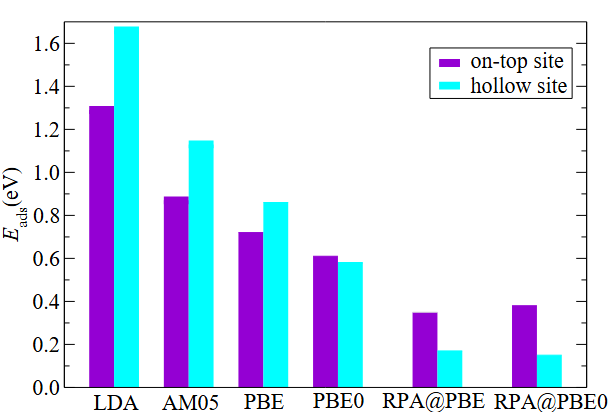
DOI:10.1007/s10853-012-6570-4
吸附能的应用
吸附能作为描述吸附物与基底相互作用的核心物理量,在催化反应设计、材料稳定性评估及高通量筛选中具有广泛应用,为材料性能优化与机制解析提供量化依据。
在催化反应设计中,吸附能是筛选活性位点的关键指标,通过比较不同表面或缺陷位点对反应中间体的吸附能差异,可识别高活性区域,例如Pd (100) 表面对O₂的吸附能(-0.8 eV)强于Pd (111)(-0.5 eV),使其在H₂O₂合成中表现出更高选择性。
同时,吸附能是微动力学建模的核心输入参数,结合过渡态理论可预测反应速率与覆盖度,如甲醇合成中,CO的吸附能通过影响表面覆盖度调控CO加氢速率,吸附能适中(-0.6eV)时可实现最高转化效率。
在材料稳定性评估方面,吸附能可量化材料的抗氧化性,例如PANI 修饰的Ti₃C₂(OH)₂表面,氧原子的吸附能越高,表明氧原子越难吸附并引发氧化反应,材料稳定性越强;此外,吸附能与空位形成能的结合可预测表面重构,如钠在Al (111) 表面的置换吸附,需计算钠原子的吸附能与Al空位形成能的总和,当总能量为负时,表面发生相变形成稳定的钠 – 铝合金层,解释了实验中观察到的表面结构变化。
在高通量筛选中,吸附能的自动化计算是加速催化剂设计的核心,依托Materials Project等数据库,结合DFT与自动化流程可并行计算数千种表面–吸附物组合的吸附能,快速筛选出潜在高活性体系,例如通过计算过渡金属合金表面对COOH的吸附能,可在短时间内从数百种合金中识别出比纯Cu活性高2倍的Cu-Au-Zn体系,大幅缩短材料开发周期。
这些应用均体现了吸附能作为“能量标尺” 在关联微观结构与宏观性能中的桥梁作用,推动了材料研究从经验探索向理性设计的转变。
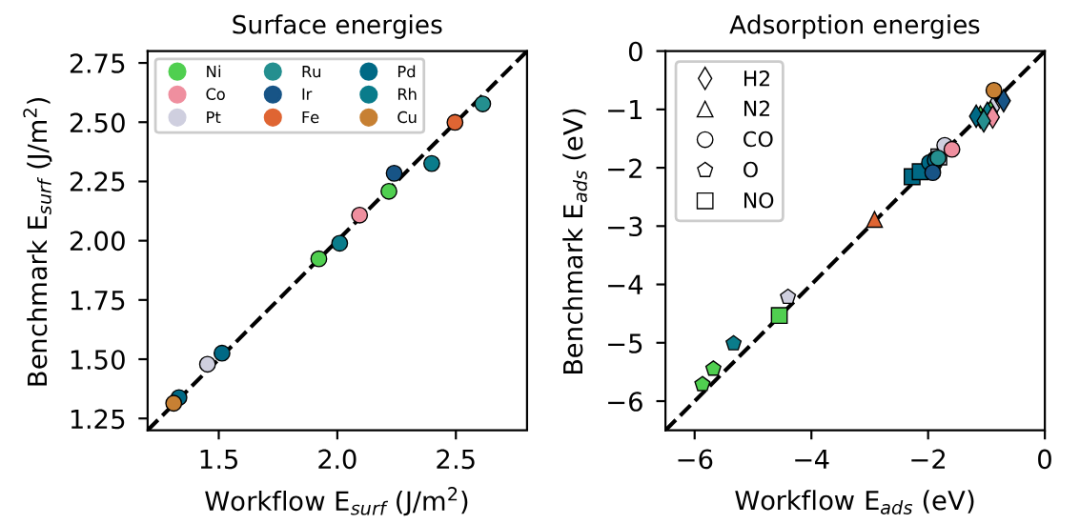
DOI:10.1038/s41524-017-0017-z
案例分析
以Ren等人利用随机相近似(RPA)研究CO在Cu(111)表面的吸附能为例,该工作系统展示了高精度计算方法在吸附能研究中的应用,为解决传统DFT方法的精度缺陷提供了范例。
其计算流程严谨且层次分明:首先进行几何优化,采用PBE泛函确定CO在Cu(111)表面的稳定吸附构型,发现顶位和空位为主要吸附位点,其中顶位的Cu-C键长短于空位,初步表明顶位吸附更强;随后进行能量计算,分别获取复合体系的总能量E(slab+B)、清洁 Cu (111) 表面的能量 E (slab) 及气相 CO 分子的能量E(B),为吸附能计算提供基础数据。
接着进行关键修正,包括基组叠加误差(BSSE)校正和零点能校正,使能量计算更贴近实际体系;最后通过RPA方法进行高阶验证,在PBE/PBE0计算结果的基础上,进一步考虑电子动态关联效应,提升吸附能计算精度。
结果与讨论部分清晰展现了不同方法的差异:RPA计算的吸附能为-0.6eV,显著低于PBE泛函的-0.2eV,这是因为RPA精准捕获了传统DFT忽略的范德华力与电子动态关联作用,与实验测得的吸附能高度吻合。
同时,吸附能的位点依赖性表明顶位吸附能低于空位,即顶位吸附更强,这与扫描隧道显微镜观测到的CO在Cu(111) 表面优先占据顶位的现象一致,直观展示了RPA数据点位于最下方,明确其相较于LDA、PBE等方法的优势。
该案例不仅验证了RPA方法在弱相互作用描述中的准确性,更确立了“几何优化 – 能量计算 – 多步修正 – 高阶验证” 的吸附能计算标准流程,为后续复杂体系的吸附能研究提供了可借鉴的方法论,推动了吸附能计算从定性描述向定量预测的发展。
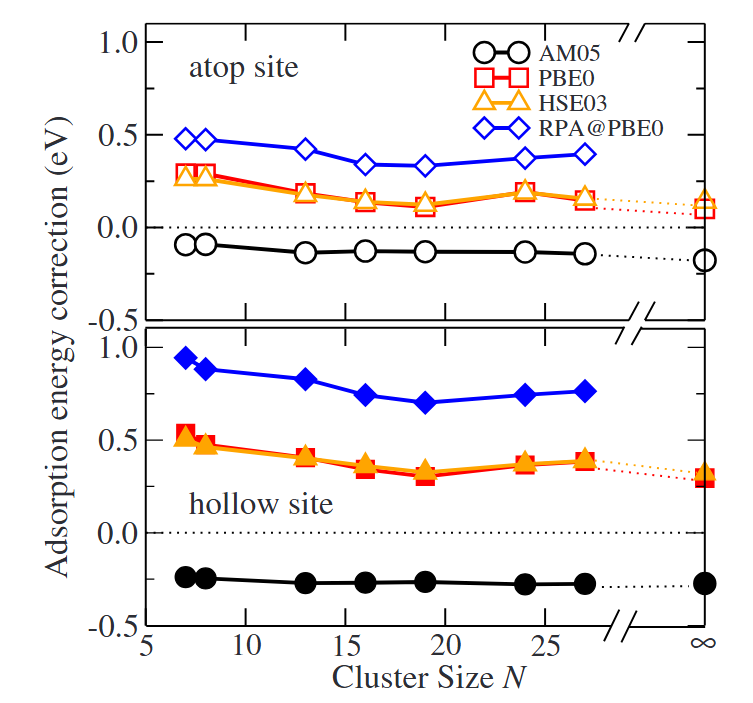
DOI:10.1103/PhysRevB.80.045402
总结
吸附能计算的发展正朝着精度与效率平衡、动态效应整合及新兴方法创新的方向推进,逐步构建起适应复杂真实体系的理论框架。
在精度与效率平衡方面,机器学习力场(MLFF)成为重要突破点,如人工神经网络模型通过DFT训练集构建吸附能预测函数,可快速扫描合金表面的CO吸附能,均方根误差低至0.13eV,计算速度比传统DFT快3个数量级,实现了高通量筛选与高精度的协同。
多尺度建模方法则通过分层处理大体系,将活性位点区域用高精度DFT描述,而周围环境用低精度分子力学处理,有效解决了无序冰表面等复杂体系的吸附能计算难题。动态效应的引入使吸附能计算更贴近实际反应条件,从头算分子动力学可模拟温度 / 压力对吸附构型的影响,例如在300K下,H₂O在Pt (111) 表面的吸附能因热振动涨落波动±0.05eV,揭示了静态计算难以捕捉的动态吸附行为。
覆盖度修正则考虑吸附物–吸附物相互作用对吸附能的微调,如H₂O₂合成中,高覆盖度的O₂会使相邻H的吸附能升高0.1eV,导致反应选择性变化,这些动态因素的整合显著提升了理论与实验的一致性。新兴方法拓展了吸附能计算的边界,非绝热耦合方法可处理光催化中的电子激发态吸附能;量子嵌入理论则精准描述金属–分子界面的电荷转移。
作为表面科学的“能量标尺”,吸附能计算精度的提升深刻影响着材料设计与机理解析,从DFT泛函选择到vdW修正,从静态计算到动态覆盖度建模,理论方法的持续迭代不断突破认知边界。未来,机器学习与多尺度模拟的深度融合将进一步解锁复杂体系的吸附行为,为能源存储、催化转化、环境治理等领域提供坚实的理论支撑,推动从原子尺度理解到宏观性能调控的全链条创新。